ith the continuous development of China higher education and the implementation of various talent plans and policies, the talent team of educational elites has continued to expand, and the flow and agglomeration of elite talents has also continued to accelerate [1]. As one of the important gathering places for scientific research institutes and educational elites in my country, the Yangtze River Delta region occupies an important position in the flow of elite talents. Taking the education elite talents in the Yangtze River Delta as the research object, collecting detailed data to analyze their flow process is conducive to deepening the understanding of the elite talent flow process, analyzing possible obstacles and problems in the flow of talents, and further optimizing the ecological environment for talent development [2,3]. Social mobility is regarded as the mutual mobility between different social groups. He distinguishes social mobility into vertical mobility and horizontal mobility and pays a lot of attention to the vertical mobility of individuals [4]. education has the function of “social choice” and plays the role of allocating social classes in modern society [5].
As the first scholar to analyze the relationship between education and social mobility, from the perspective of functionalism, he analyzed the class mobility of social groups and created social mobility, an important research branch of sociology [6]. The publication of the book “Occupational Structure in America” analyzes the intergenerational social mobility of families from the perspective of “status acquisition”, discusses the relationship between the educational level of the parents and the occupational status of the offspring, and pioneered the study of social status mobility at the individual level. new angle [7]. Subsequent research continued to discuss education and social mobility (class inequality) from this topic. After proposing the concept of “social capital”,[8] researched education and social mobility more deeply, to the publication of “Social Capital: Social Structure and Action”, which pointed out that an individual’s family status affects his access to different levels of higher education, which in turn determines the social capital of his career development, thereby raising the theoretical level of this research field to a new height [8]. Domestic scholars have also paid attention to this research topic [9]. As pioneering research in this field, based on the documents of the Qing Dynasty, quantitative methods were used to discuss how the imperial examination system, an educational screening process, opened a path for social mobility [10].
Subsequently, this research field gradually fell silent until the great changes in education in the expansion of college enrollment in the new century, the promotion of quantitative research methods in sociology, and the launch of various national large-scale surveys, which promoted the explosion of research results in this field [11,12]. Relevant research focuses on words such as “educational equality”, “status acquisition” and “class solidification”, and discusses the issue of education and family intergenerational social mobility from the macro-institutional level and the micro-level family impact level [13]. In the follow-up research, the types of social mobility are gradually distinguished, for example, they are divided into intergenerational mobility and intragenerational mobility according to the scope of mobility, structural mobility and free mobility according to the reasons for mobility, and the mechanism distinguishes them into competitive flows and sponsored flows, etc [14].
In research on education and social mobility, most of them analyze the issue of intergenerational social mobility from the perspective of class inequality, and there are few studies on intragenerational social mobility of educational talents.
The main contributions of this research are 3 points:
Introducing big data analysis into the analysis of the influence of education flow of music professionals.
A novel resume analysis method was designed and the index of constructing the flow quadrant was explored.
Experiments show that our method has good advantages and can focus on the intra-generational social mobility of educational elites, and we expect to find out about this social mobility process.
For the different directions of social mobility of educational elites, there are not only gradient distinctions made from the changes in the reputation grades of colleges and universities before and after migration, but also cross-level mobility statistics based on the changes in urban grades before and after migration [15] but the selected dimensions are relatively single. When analyzing the problem of talent mobility, the equal importance of local stratification and institutional reputation hierarchy is emphasized [16]. In the research, the change of academic reputation grade mainly considers the change of university grade before and after the movement. The flow between universities and research institutes cannot be compared directly, so it is analyzed when discussing the flow of institutions according to the situation [17]. As shown in Figure 1, the ordinate is the change in the reputation level of the institution. The rankings of the universities before and after the education elites moved are compared, and the universities with higher rankings are positive, and vice versa (the ranking of each university is 20.03— Average number of ARWU rankings in 2020, divided into four and five categories). In the process of changing social status, the advantages and disadvantages of resources possessed by individuals have a certain complementary effect [18]. Therefore, when the change of the reputation level of the institution and the change of the geographical stratification are positive and negative, it is classified as a parallel flow.
Inferential statistics is a relatively young part of statistics and even psych statistics [19]. It relies on statistical results to prove or disprove a proposition. Specifically, by analyzing the difference between the distribution of the sample and the sample, it is to estimate the difference between the sample and the population, the pre- and post-test scores of the same sample, the score gap between the sample and the sample, and whether the score gap between the population and the population is significantly different. For example, we wanted to study whether educational background affects a person’s performance on an intelligence test. You can find 100 24-year-old college graduates and 100 24-year-old junior high school graduates [20]. Collect some of their intelligence test scores.
In the recommendation system, the most important thing to determine the recommendation performance is the recommendation algorithm. At present, this algorithm is widely used, especially in the industrial field. The second is a recommendation algorithm based on collaborative filtering. In the process of applying this algorithm, it is mainly based on matrix decomposition. The composition of the matrix is mainly the user behavior information formed by the recommendation system. When applying this method, the user’s previous preference status is referred to realize the recommendation.
This paper mainly combines music professional research and recommendation system and proposes a hybrid recommendation algorithm to analyze the mobility of music professionals.
There may be complex application scenarios in actual recommendation, and a single recommendation algorithm cannot meet the actual application requirements. At this time, hybrid recommendation emerges as the times require, which can effectively solve the problems and shortcomings of a single algorithm. Common hybrid recommendation algorithms include weighted, Switching, hybrid.
Deep learning has gradually become a hot spot of attention in recent years. Among them, CNN is an efficient recognition method, which is widely used in speech recognition, image recognition and other fields. This method is used to solve large-scale machine problems. For learning problems, compared with traditional machine learning, this algorithm is better in both recommendation efficiency and recommendation quality. Based on the CNN and combining it with various music tag features, this paper proposes a recommendation algorithm with better recommendation effect. Compared with the traditional recommendation algorithm, this algorithm refers to the user’s historical data. And it is combined with the acoustic features corresponding to music audio to construct the corresponding CNN regression model, and the Embedding layer is used to mine the music tag information to complete the personalized recommendation. The research carried out in this paper can be used as a supplement to the music recommendation algorithm, which can effectively solve the problems of low recommendation accuracy and insufficient feature analysis in traditional recommendation systems, to better meet the needs of personalized recommendation. The overall design block diagram of the recommendation system constructed in this paper is shown in Figure 1:
Cross cultural communication ability and civil aviation cabin culture (see Figure 1).
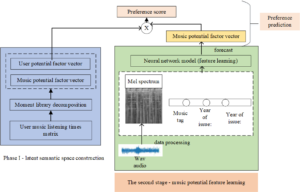
The obtained data set contains the relevant records of users listening to music, which can be regarded as implicit feedback. For the implicit score. After specific data processing, a class of users with a certain level of sparsity—the music matrix, is obtained with a score corresponding to music based on the relative playing times.
Extracting the characteristics of music audio through digital signals can effectively solve the huge and complex calculation problem that needs to be carried out when directly processing the original data, and the obtained characteristics are more distinct, which can be processed and processed more conveniently. use. There are various methods that can be used to analyze audio features, such as spectrogram and mel spectrum. Therefore, this paper extracts the Mel spectrogram of the audio resources in the dataset and uses it as the input content in the subsequent training. At the same time, the Embedding layer can also be used to integrate other information of singers and music for music information mining. If the feature domain corresponding to the model is, the one-hot vector corresponding to the jet eigenvalue contained in the feature is represented by this encoding. In the embedding layer, each feature has its corresponding embedding matrix, and the Embedding vectors are spliced together after learning by a multi-layer perceptron to obtain the input of the next layer. In general, we first process the continuous audio signal, pre-emphasizing, framing, and windowing it; then process all short-term analysis windows through FFT, so that the corresponding spectrum is obtained; then the spectrum is based on a Mel scale filter The Mel spectrum can be obtained; then the logarithm of the above Mel spectrum can be obtained, and the whole extraction process can be completed. In the research of this paper, we introduced LaRosa in the python toolkit for processing and analysis, mainly for the detailed analysis of music audio. Based on the processing function specs how in the LaRosa toolkit, where the horizontal axis represents time and the vertical axis represents frequency, a 256×256 Mel spectrogram is finally obtained.
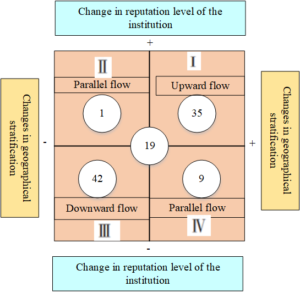
According to the previous calculations, there are 282 scholars who stay in their alma mater or do postdoctoral studies after graduating with a doctorate, and 339 scholars who have a mobility experience from their doctoral graduation to their first job after graduation. As shown in Figure 2, among the 339 scholars on the move, the parallel mobility is the largest, with 139 scholars, accounting for 41.0%. Followed by upward mobility, there are 112 people, accounting for 33.0%, close to one third. The downward flow is again, with 88 people, accounting for 26.0%. Among the parallel migrants, the “double-same” type of flow at the same university level and the same city line level is the main type, reaching 127, accounting for 91.4% of the parallel migrants. There are only very few examples of the flow of “upgrading city and lowering school” that raises the city line level but lowers the academic reputation level of colleges and universities, and the flow of “downgrading city to school” that lowers the city line level but raises the academic reputation level of colleges and universities.
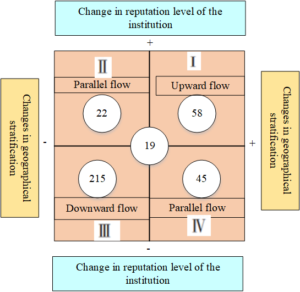
In general, in the process of mobility from doctoral graduation to the first job after graduation, the educational elites in the Yangtze River Delta still tend to maintain or improve their mobility quadrant to maintain the academic cooperation network and promote the improvement of academic capital. Further analysis of the mobility of educational elites from the initial work institution after doctoral graduation to the work institution when they were elected as “Changjiang Scholars” shows that there are 318 scholars with mobility experience. As shown in the mobility quadrant in Figure 3, the number of downward mobility increased significantly, reaching 215, accounting for 67.6% of the mobility elite. There are 58 people who move upwards, accounting for 18.2% of the mobile elites; 45 people who move in parallel, accounting for 14.2% of the elites. Among the parallel migrants, there are 22 people, accounting for 48.9% of the parallel migrants, nearly half of which are those who lower the city line level but improve the academic reputation of the university. The second is the “double-identical” type of flow at the same university level and the same city line level, accounting for 42.2%. Only 8.9% of the flow of “upgrading cities and downgrading schools” was to raise the city line level but lower the academic reputation level of colleges and universities. The main reason for the large proportion of downward mobility is that among this group of educational elites, there are 297 people who are engaged in post-doctoral work after graduation. Fifty-two of them continued to work in their alma mater after leaving the station, while the rest found other jobs. Most of the institutions they ended up working for were inferior to their post-doctoral service institutions and work cities in terms of academic reputation and city level.
The music metadata used in this paper is all obtained through the Million Songs Dataset (MSD), and all the data related to the user’s listening situation are obtained through the Echo Nest Taste Profile Subset, a subset contained in the MSD. After obtaining the corresponding data, this paper firstly spares the data. Considering the overall time cost, this experiment only extracts any 3s audio from a certain channel and presents it in wav format when fetching data. After obtaining the audio data, it is divided and processed to ensure that the formats of different data have high consistency.
This paper evaluates based on the two dimensions of scoring accuracy and list accuracy. Common standards used to measure the accuracy of prediction scores are mean absolute error (MAE), normalized mean absolute error (NMAE), mean squared error (MSE), and root mean square error (RMSE). In the research process of this paper, we introduce the above four indicators for evaluation. The recommendation algorithm studied in this paper can achieve Ton recommendation by multiple users’ music ranking can be achieved for all users, and then the top N music can be determined to form a list and recommended respectively. To test the accuracy of this list, in this study, we evaluate the recommendation quality through the precision rate, recall rate, and F1 value, respectively, to test the accuracy of the experiment.
Using the training set data to train the CNN network model, the training results found that when the number of iterations of the training continued to increase, the loss error of the model decreased rapidly at the beginning, and as the number of iterations increased, the decreasing trend gradually slowed down. Near 10, the error starts to level off. To verify the validity of the model, the experiments are analyzed and evaluated from different angles. Choice of latent factor dimension k and number of iterations. Root mean square error RMSE was applied over the overall experimental period, based on which the accuracy of the predicted scores was judged. For different feature dimension k and training round epoch, the finally obtained model prediction score RMSE is shown in Figure 4.
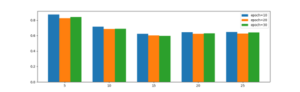
When the latent factor k is 15 and the training round epoch is 20, the experiment can achieve a better score prediction effect. Comparison and analysis of the recommendation results of different recommendation models. This paper uses the MSE, RMSE and MSLE algorithms to conduct a comprehensive evaluation of the model training effect. And used Frunk-SVD, User-CF and CB and other algorithm models for comparative analysis, and finally obtained the accuracy rate, recall rate, and F1 value corresponding to different recommendation list lengths. Each method and the method in this paper are implemented using Kera’s, and the optimizer uses Adam, which mainly includes audio information and other identification information. Through the analysis of the four error indicators, all the indicators are lower than other models, indicating that the latent factor vector in the process of prediction, the actual effect is better than other models. In the evaluation of recommendation tasks, this paper uses recall rate, F1 value and precision rate as evaluation criteria. The Top N recommendation strategy is used to form the required recommendation list. When the value of N is different, the results are also different. The results are shown in Figure 5, Figure 6 and Figure 7.
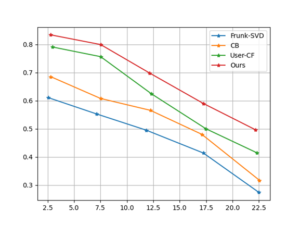
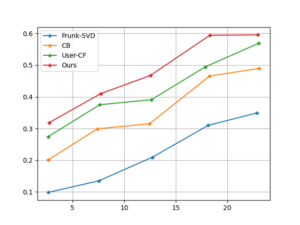
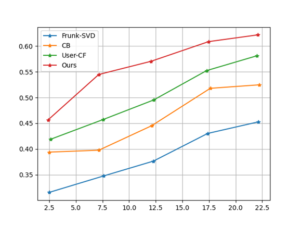
It can be seen from the figure that when the length of the recommendation list is the same, the F1 value, precision rate and recall rate are better than other models. This is because the traditional recommendation algorithm model only uses a relatively sparse scoring matrix and does not fully utilize it. Other related properties of music. Because the deep convolutional neural network can better learn the characteristics of the data, the recommendation algorithm in this paper adds the relevant content of deep learning, and combines the relevant attributes of the music tags, so that the recommendation effect can be better improved.
This paper uses data analysis and recommendation system technology to conduct a comprehensive analysis of the career development and mobility of music talents. We propose a deep neural network model that combines various music identification information with traditional recommendation algorithm models. To verify the feasibility of the recommendation algorithm proposed in this paper, the experimental results are comprehensively evaluated and analyzed from the aspects of recommendation accuracy, recall, and F1 value. The final experimental results show that the recommendation algorithm in this paper makes the final recommendation result better than the traditional recommendation algorithm models such as Frunk-SVD, User-CF and CB.




