s an international language, English plays an important role in communication [1]. Although English teaching in China’s colleges and universities has made considerable achievements, there are still some problems, ignoring the practical application of English, especially the cultivation of oral communication skills [2-3]. Multidimensional interactive teaching mode abandons the single static teaching mode of “teacher-centered” and advocates the multidimensional interactive teaching mode of “student-centered”, which takes the cultivation of students’ listening, speaking and communicative ability as the ultimate goal [4-6]. The implementation of multi-dimensional interactive teaching mode in college English teaching is of great significance to the active classroom atmosphere, the construction of good teacher-student relationship, and the enhancement of students’ English application ability [7-8].
The so-called multi-dimensional interactive teaching is a kind of student-centered teaching mode that constructs the classroom theme structure through teacher-student interaction, student-student interaction, group interaction, etc. [9-10], which mainly guides students to actively participate in the teaching mode, improves their English application ability and cultivates group consciousness for the purpose [11]. We strongly advocate independent, cooperative and inquiry learning, so that students can truly experience the beauty of learning, and then let students realize the joy of success.
In designing the classroom interactive course teaching, English in colleges and universities should adhere to the principles of human-centered teaching, understanding learning, constructivism, systematic teaching and learning, and role learning [12]. Since students in colleges and universities are not interested in English courses, most of them enter the institutions only with the hope of having a good career and getting a position where they can survive, while few of them really learn for the sake of learning. Therefore, the English courses in colleges and universities should not only strengthen students’ basic English skills such as listening, reading and writing, but also add English courses for special purposes, so as to lay a solid foundation for students to engage in the relevant industries in the future, and fully embody the concept of the human being, and at the same time, meet the different learning needs of students, and cultivate more applied talents for the society [13]. The planning of the curriculum should fully respect the actual needs of students’ hearts, deal with the relationship between classroom teaching, online teaching and extracurricular tutoring, and carefully design the specific implementation process in the teaching program [14].
Literature [15] suggests that despite the great popularity of English as a language teaching in policy discussions, little research has been done to examine whether it is effective in meeting the emerging needs of a growing multilingual student population. Literature [16] emphasizes the importance of interaction, stating that in the university English classroom, teachers should provide students with equal opportunities to interact through communicative and collaborative activities in order to develop their full potential. Literature [17] mentions that COVID-19 has led to the transition of higher education to “distance and emergency teaching” worldwide, which will have a long-term impact on English language teaching and learning in multilingual university environments. Literature [18] analyzed that the development of learners’ communicative willingness and communicative enjoyment had no predictive value for performance in oral English interaction, but the development of self-confidence explained performance in oral English interaction in training interaction situations. Literature [19] mentions that the use of selected questions from the MM alphabet helps to heuristically guide the iterative integration process and provides richer explanations that deepen the understanding of the implementation and impact of complex classroom interventions. Literature [20] applies the integration of digital and face-to-face interactions as well as the integration of locational social media in classroom teaching to better reflect the concept of student-centered teaching and learning, and the use of modern new media technology in teaching is also an innovation in teaching English in higher education. Literature [21] suggests that interactive read-alouds of informational texts can facilitate literacy learning by promoting cooperative and respectful discussions among students.
Firstly, based on the English text data categories, the research data are obtained based on three different data collection methods, and the TF-IDF text feature algorithm is used to extract text features from the data. Then, based on graph convolutional neural network, the text features are labeled with named entities, and the data format is unified and stored in the Neo4j database, so as to complete the design of English cognitive knowledge mapping. Then, based on the development requirements of English teaching, an interactive English teaching model integrating cognitive knowledge mapping is proposed, and its principles and implementation paths are comprehensively elaborated and analyzed. Finally, we set up experimental groups and control groups, and selected research tools to test and analyze the effectiveness of the English interactive teaching model proposed in this paper.
There are three main types of data sources for English cognitive knowledge mapping, the first is structured data stored in databases, such as exercise data in learning platforms, the second is semi-structured data on the web, such as textual data of English knowledge points and example sentences on encyclopedic websites, and the third is words, phrases, and sentences data from unstructured units or chapters in authoritative books, and data from different sources Different sources of data require different processing. For structured data that already exists in the database, since this kind of data is manually entered and checked by professional personnel, it can be directly exported using Excel tables in accordance with the standard format of entity relationships. Semi-structured data stored in sources such as encyclopedic websites on the web can be crawled using the SCRAPY crawler framework for knowledge concepts and example sentences, which are stored in the database in a structured way, while for unstructured data from books, the relevant knowledge points are entered into the database using manual processing.
For the elementary school English knowledge point name and structure and other information, is the student learning the most basic content, need to use the authority of the book to obtain, this paper uses the college university English textbook of the human education version, through manual organization and generalization, there are 4 major categories of knowledge points, respectively, letter phonetics, lexical, syntax and tense. Alphabetic phonetics contains 2 categories and 7 subcategories of knowledge points, lexicography contains 9 categories and 27 subcategories of knowledge points, syntax contains 5 categories and 12 subcategories of knowledge points, tenses contain 4 categories and 11 subcategories of knowledge points.
Structured exercise data is derived from the learning platform, all the exercise data is manually entered into the database by professionals, after the statistical system there are 54,387 exercise data, the type of questions are multiple-choice, fill-in-the-blanks, classification and oral questions, involving the college English knowledge point information are alphabetic-phonetic, lexical, syntactic, and tense of these four categories.
For the data related to the knowledge point concepts and example sentences of elementary school English, it is very time-consuming to use manual processing, by using crawler technology for data acquisition can be fast to achieve the expected results, because the encyclopedia website above contains rich semantic text information, so Baidu encyclopedia as a source of knowledge point concepts and examples of data, using the now popular SCRAPY crawler framework for data crawling,. SCRAPY library is a very process data crawling package, which sets up a web machine crawler in an automated way to programmatically extract key data from online web pages. Crawling data through the crawler there are missing, repetitive and mixed Chinese and English and other phenomena, you need to filter and clean, for some of the missing data, you need to make up for the repetitive data de-emphasis operation, the Chinese and English text using the relevant regular expressions filtering process, data preprocessing is completed to generate the CSV format can be.
A vector space model is a mathematical or algebraic model for the transformation and representation of text documents as numerical vectors of specific lexical items that form vector dimensions. Suppose the document vector space is represented by VS and suppose there is a document in VS \(D\). Then each document dimension and the number of column vectors will be the total number of different lexical items or words in all the documents in the vector space VS. Thus, the vector space can be represented as (1): \[\label{GrindEQ__1_} VS=\left\{W_{1} ,W_{2} ,\cdots ,w_{n} \right\} ,\tag{1}\] where \(n\) is the number of distinct words in the full document. Document \(D\) is represented in vector space as in (2): \[\label{GrindEQ__2_} D=\left\{W_{D1} ,W_{D2} ,\cdots ,W_{Dn} \right\} .\tag{2}\] In (2), \(W_{Dn}\) represents the weight of the \(n\)rd word in document \(D\).
This weight is a quantitative value that can represent the frequency of words in the document, the average frequency of occurrence, or the weight of TF-IDF.
TF-IDF uses statistical methods to measure the contribution of each word to the document. The basic idea is that if the more important a document is to a document, the greater the probability of it, but in the process of designing, in the process of design, if the word appears to be more frequent in the entire corpus, the difference in the file will be reduced, and the importance will be reduced, and the importance of the language will be reduced, and the language data problem will be well processed.
The bag-of-words model is simple, but the vectors are completely dependent on the absolute frequency of word occurrences. This poses some potential problems in that words that occur more frequently in all documents of the corpus will have a higher frequency and these words will affect other words that do not occur as frequently as these words, but are more meaningful and effective for document categorization.
TF-IDF is an algorithm that calculates the weights of words in a document as a combination of two metrics: word frequency and inverse document frequency. Mathematically, using \(tf\) for word frequency and \(idf\) for inverse document frequency, it can be expressed as in (3): \[\label{GrindEQ__3_} tfidf=tf\times idf.\tag{3}\] The word frequency of any document is the value of the raw frequency of occurrence of the word in a particular document, if \(f_{w_{D} }\) denotes the frequency of word \(w\) in document \(D\), then the word frequency can be expressed as in (4): \[\label{GrindEQ__4_} tf\left(w,D\right)=f_{w_{D} }.\tag{4}\] \(idf\) represents the inverse document frequency, that is, the inverse of the document frequency of each word which is calculated by taking the ratio of the total document to the frequency of each word and applying a logarithmic method to transform the ratio. Mathematically, it is expressed as (5): \[\label{GrindEQ__5_} idf\left(t\right)=1+\log \frac{C}{1+df\left(t\right)},\tag{5}\] where \(idf\left(t\right)\) denotes the \(idf\) of word \(t\), \(C\) denotes the total number of documents, and \(df\left(t\right)\) denotes the frequency of the number of documents containing word \(t\). Denoting the Euclidean L2 paradigm of the matrix by \(\left\| tfidf\right\|\), then the final \(tfidf\) eigenvector is expressed as in (6): \[\label{GrindEQ__6_} tfidf=\frac{{\rm \; }tfidf{\rm \; }}{\left\| tfidf\right\| }.\tag{6}\]
In conclusion, the TF-IDF algorithm tends to filter out the common words and keep the important words, which is very important for text feature extraction, which makes the features of the data more obvious and enables to represent the importance of the words among the documents.
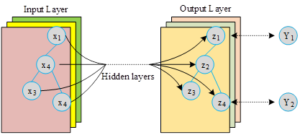
The structure of graph convolutional neural network is shown in Figure 1, graph convolutional neural network is a neural network model that performs convolution operation on graphs, which is similar to the convolution operation in convolutional neural network in many ways, such as weights sharing, local connection, multilayer network and so on. There are many exercise nodes and interconnected edges on the middle school English cognitive knowledge graph, when representing one of the exercise nodes, the model will use its surrounding nodes to represent this node, which is the process of graph convolution. In the process of convolution, the features of the exercise nodes around the exercise node will have an impact on the representation of the current exercise node, the essence of this process is feature extraction, as the number of times the model is trained increases, deeper features are extracted. Graph Convolutional Neural Networks have multiple hidden layers, and in multilayer graph convolutional neural networks, the propagation rule between layers is defined by (7): \[\label{GrindEQ__7_} H^{\left(l+1\right)} =\sigma \left(\breve{D}^{-\frac{1}{2} } \left(A+I_{N} \right)\breve{D}^{-\frac{1}{2} } H^{\left(l\right)} W^{\left(l\right)} \right) ,\tag{7}\] where \(A\) represents the adjacency matrix of the middle school English cognitive knowledge graph, \(I_{N}\) represents the corresponding diagonal array of the middle school English cognitive knowledge graph, and \(A+I_{N}\) represents the self-connection added to the adjacency matrix of the middle school English cognitive knowledge graph, i.e., assuming that the middle school English cognitive knowledge graph has edges connecting exercise nodes themselves to themselves, the middle school English cognitive knowledge graph with the addition of self-connections can avoid the loss of features in the training of the graph convolutional neural network. Losing features when training the graph convolutional neural network, which makes the learning effect of the model better. \(D^{{-1\mathord{\left/ {\vphantom {-1 2}} \right. } 2} }\) and \(W^{\left(1\right)}\) denote the weight matrix to be learned in layer 1, \(H^{\left(t\right)}\) denotes the state matrix of the hidden layer in layer 1, and \(\sigma\) denotes the activation function of the current hidden layer, which can be any activation function, and here we choose the RELU function, which is defined in (8): \[\label{GrindEQ__8_} f\left(x\right)=\left\{\begin{array}{ll} {0} & {x\le 0} \\ {x} & {x>0} \end{array}\right..\tag{8}\] The convolution of graph convolutional neural networks can be broadly categorized into two types: spectral convolution and spatial domain convolution. Spectral convolution refers to processing the filter and graph signals in the graph convolution network in the Fourier domain, and spatial domain convolution refers to connecting the nodes in the cognitive knowledge graph in the spatial domain, so that the nodes in the spatial domain reach a hierarchical relationship, and then later perform the convolution operation in the spatial domain. Equation (7) is the most basic convolutional propagation in graph convolutional neural networks, this propagation can be replaced by using the n-order approximation of the local spectral filter on the cognitive knowledge graph thereby simplifying the computation, reducing the amount of computation, and accelerating the speed of the model computation, so in this paper we use the spectral convolution, which transfers the filter and the graph signals in the graph convolutional network to the Fourier for computation.
The spectral convolution mode of the graph can be defined as the product of the graph signal \(x\in R^{N}\) and the filter \(g_{\theta } =diag\left(\theta \right)\). In order to facilitate the computation in the Fourier domain, the filter is parameterized in the Fourier domain \(\theta \in R^{N}\) as in (9): \[\label{GrindEQ__9_} g_{\theta } *X=Ug\left(\lambda \right)U^{T} X,\tag{9}\] where \(U^{T} x\) is the graph Fourier transform of \(x\), \(g\left(\lambda \right)\) is a function of the eigenvalues of the graph Laplace matrix, \(U\) is a matrix consisting of the eigenvectors of the normalized graph Laplace matrix, and \(\lambda\) is a diagonal array consisting of the eigenvalues of \(L\). The graph Laplace matrix is computed as in (10): \[\label{GrindEQ__10_} L=I^{N} D^{{-1\mathord{\left/ {\vphantom {-1 2}} \right. } 2} } AD^{{-1\mathord{\left/ {\vphantom {-1 2}} \right. } 2} } =UAU^{T}.\tag{10}\] The above equation can be computed on a small-scale graph, the cognitive knowledge graph of middle school English in this paper contains 9449 exercise nodes, the graph size is relatively large, the complexity of computing the eigenvalue decomposition of the graph Laplace matrix will be very high, and the model computation time will become longer, in order to solve the problem, in this paper, we use the expansion of the Chebyshev polynomials of the \(k\)nd order of the Chebyshev polynomials \(T_{k} \left(x\right)\) to approximate the replacement of the \(g\left(\lambda \right)\), as in (11): \[\label{GrindEQ__11_} g^{\sim } \left(\lambda \right)\approx \sum _{0}^{k}\theta _{k}^{\sim } T_{k} \left(\lambda ^{\sim } \right) ,\tag{11}\] where \(\lambda ^{\sim } ={2\lambda \mathord{\left/ {\vphantom {2\lambda \lambda _{\max } }} \right. } \lambda _{\max } } -I_{N}\), \(\lambda _{\max }\) denote the largest eigenvalues of \(L\), and \(\theta \in R^{k}\) is the Chebyshev coefficient vector. According to the definition of Chebyshev polynomials: \(T_{k} \left(x\right)=2xT_{k-1} \left(x\right)-T_{k-2} \left(x\right)\), where \(T_{0} \left(x\right)=1\), \(T_{1} \left(x\right)=x\), thus (9) can be written in the form of (12): \[\label{GrindEQ__12_} g\theta *x\approx \sum _{k=0}^{k}\theta _{k} T_{k} \left(\frac{2}{\lambda _{\max } } L-I_{N} \right)x.\tag{12}\] The \(k\)st order Chebyshev polynomials used in the above equation and the Laplace polynomials as in (6) are also of \(k\)nd order, which means that the representation of a particular node in the cognitive knowledge graph of middle school English only depends on the exercise nodes with a path length of \(k\) or less. Multiple convolutional layers can be stacked in the graph convolutional neural network, each of which consists of the above Eq. (9), and with the increase of the number of convolutional layers, the parameters in the model also increase, which leads to the emergence of the problem of slow model computation and overfitting, in order to prevent the emergence of the above problems, in this paper, the number of convolutional layers is set to 2, and its forward propagation model can be simply written as Eq. (13): \[\label{GrindEQ__13_} Z=f\left(X,A\right)=soft\max \left(\widetilde{A}RELU\left(\tilde{A}XW^{0} \right)W^{1} \right) ,\tag{13}\] where \(W^{0}\) is the weight matrix of the first convolutional layer, \(W^{1}\) is the weight matrix of the second convolutional layer, \(\tilde{A}=\tilde{D}^{{-1\mathord{\left/ {\vphantom {-1 2}} \right. } 2} } \left(A+I_{N} \right)\), \(\tilde{D}^{{-1\mathord{\left/ {\vphantom {-1 2}} \right. } 2} }\) Cognitive Knowledge Graph for Middle School English Exercises After going through the forward propagation model, the category probability of each node will be obtained.
Since the initially obtained English grammar data format is still somewhat different from the data format required for the conceptual model of cognitive knowledge mapping, the data format needs to be unified. The unified data format contains the unified entity data format as well as the relational data format.
Entity Data Format
The entity design in the design of cognitive knowledge graph contains four types of entities: word knowledge point name, word knowledge point concept, word knowledge point example vocabulary, sentence knowledge point structure vocabulary. Among them, the word class knowledge point names are screened and obtained from authoritative grammar books and curriculum standards. The vocabulary of lexical knowledge point concepts and knowledge point examples is obtained by Baidu encyclopedia crawler. However, the entity of the structure vocabulary of sentence-type knowledge points has not been obtained directly, so it is necessary to split the grammatical structure into individual structure vocabulary and establish the corresponding entity table.
Relational Data Format
In the relationship design of the conceptual layer of cognitive knowledge mapping, the relationships of cognitive knowledge mapping are divided into four major categories: A contains B relationship, A concept B relationship, A example B relationship, and A sentence class grammar name B relationship. The A contains B relationship is obtained from authoritative grammar books and curriculum standards, and the A concept B relationship and A example B relationship are obtained from the Baidu encyclopedia crawler. The A sentence class grammatical name B relationship is not directly obtained, and it needs to be reformatted according to the sentence class grammatical structure vocabulary entity table in the entity design.
In recent years, the storage of cognitive knowledge graphs is dominated by graph databases, and Neo4j graph databases have been widely used due to their flexible design, efficient performance, and simplicity. In Neo4j graph database, nodes represent entities and edges represent relationships between entities.
When doing data import, you can use the official Neo4j-import tool for batch import, or you can use the LOAD command to import in the web interface of Neo4j graph data. Whichever way is chosen, each type of entity and relationship needs to be saved as a CSV file before importing. After obtaining the exact CSV file, it needs to be placed in the import folder in the root path of the Neo4j installation to facilitate subsequent imports. When batch importing the files, it is easy to have the problem of Chinese anomalies, resulting in Chinese characters not being displayed properly in the mapping. The names of the knowledge points in the English Grammar Cognitive Knowledge Atlas are all Chinese characters, so it is necessary to modify the encoding format of the CSV file to “UTF-8, no BOM format”.
In this paper, we choose the LOAD command in the Neo4j graph database to import CSV files in bulk, and the CSV files in this paper are the 4 entity tables and 18 relationship tables of the cognitive knowledge mapping. In the process of importing Neo4j graph data using LOAD command, the names of the relationships also need to be named. In order to facilitate intuitive understanding, in this paper, the 18 relations are directly named as containment, concept, example, imperative, inversion, passive voice, virtual voice, definite article, gerund, general present tense, general past tense, general future tense, past perfect, present perfect, future perfect, present progressive, past progressive, future progressive.
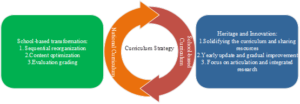
Based on the technical foundation of cognitive knowledge mapping, looking at all aspects of English teaching, this study considers the individual learning differences of different students, the clever use of cognitive knowledge mapping to enrich the content of teaching and carry out the study of students’ personalized learning resources pushing, and the significance of the English interactive teaching model that integrates cognitive knowledge mapping is shown in Figure 2. Learning resources pushing based on the cognitive knowledge map background does not require a comprehensive and grandiose smart classroom, but focuses on one point. To realize this function, it is necessary to prepare a database containing the knowledge points of classroom teaching and a database of questions related to the knowledge points. The English interactive teaching model integrating cognitive knowledge mapping firstly regards the teaching process as a dynamic development of teaching and learning unification process, in which teaching and learning interact with each other and interact with each other, and secondly regards the teaching process as a process of life-long communication and interaction between teachers and students. Classroom interactive teaching mode is also a special mode of teaching structure. Its special features are reflected in the following two aspects: optimizing “teaching interaction” by regulating teacher-student relationships and interactions to form harmonious student-student interactions and teacher-student interactions; and improving teaching effectiveness by giving full play to the students’ subjectivity, improving students’ ability to learn on their own and cultivating students’ positive emotional attitudes. This study will focus on the positive role of English cognitive knowledge mapping in the innovation of teaching mode in the subsequent research.
The two classes, totaling 80 students, were divided into experimental and control groups on a class basis, all of which were students in the class of 2022 majoring in English (international English direction) in a university. The teaching mode was implemented from March 2022 to December 2022, a total of two semesters, 4 credit hours per week, a total of 40 teaching weeks, a total of 140 credit hours. Students in both groups took a pre-test of their English performance prior to the implementation of the instructional model, with the purpose of measuring inter-group differences. An interactive English teaching model incorporating cognitive knowledge mapping was then used for the experimental group of students, while the control group of students was taught using traditional teaching methods. At the end of the course, the two groups of students took another English achievement posttest. It was attempted to confirm through the post-test that the English interactive teaching mode incorporating cognitive knowledge mapping had a facilitating effect on students’ English learning. In order to avoid the negative impact of the unknown factors in the evaluation system of the new teaching model on students’ evaluation of excellence and scholarships, the experimental group practiced the parallel approach of the old and new evaluation systems, evaluating the students according to the two standards at the same time.
By using tools such as questionnaires and quizzes to systematically analyze and summarize the subjects of the study, in this research process, a pre-test was administered to the experimental and control groups in order to test the degree of approximation of the original levels of the two groups, while a post-test was administered to the two groups in order to test the degree of difference between the two groups in terms of their existing levels after the experiment. When analyzing the results of the posttest, an independent samples t-test was conducted in addition to comparing the mean scores of the two groups. The posttest results of the control group and the experimental group were analyzed using the software SPSS 19.0 to compare the pre-test and post-test scores of the two groups, and it was concluded that interactive teaching incorporating Cognitive Knowledge Mapping in the experimental group was able to improve the students’ English performance, and at the same time, their linguistic competence, communicative competence, and cooperative skills were also exercised.
Analysis of pre-test data
In order to observe that there is no significant difference between the pre-test scores of the two groups of students, a test of variance (T-test) is required.There are two prerequisites for the use of the T-test: normal distribution of the data and chi-squaredness of the variance.
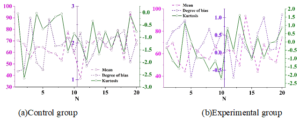
Before implementing the study, students in the experimental and control groups were tested using SPSS 19.0, and the following descriptive analysis was obtained.The results of the analysis of the pretest data of English achievement are shown in Figure 3, where (a)\(\mathrm{\sim}\)(b) are the control and experimental groups, respectively, and the results show that the mean scores of the experimental and control groups are 61.86 and 61.95, respectively, which are not significantly different from each other. The skewness values are 0.185 and 0.336 respectively, which are positively skewed, and the kurtosis values are -0.656 and -0.389 respectively, indicating that the simulation test is slightly difficult, and it is slightly more difficult for the experimental group.
Variance test
Under the “Analysis” tab of SPSS17.0, we get the normality test, and the results of the test for the differences in English scores are shown in Table 1, according to the value of Sig under Kolmogorov-Smirnov in the table, we can judge whether the data obeys the normal distribution or not: when the value of Sig is greater than 0.05, the data obeys the normal distribution. Normal distribution. When the Sig value is less than 0.05, the data does not obey normal distribution.Under the Kolmogorov-Smirnov column, the Sig value of the experimental group and the control group is 0.217, which is greater than 0.05, while under the Shapiro-Wilk column, the Sig value of the experimental group and the control group is 0.968, 0.968, which means that the English performance of the pre-test of the experimental group and the control group is not significant, it can be seen that the scores of the two groups are basically normally distributed, and the Sig value (bilaterally) is 0.940, which is greater than 0.05. Thus, it can be seen that there is no significant difference between the pre-test scores of the experimental group and the control group.
| Name | Kolmogorov-Smirnov | Shapiro-Wilk | ||||||
| Statistic | Df | Sig | Statistic | Df | Sig | |||
| Pretest of control group | 0.109 | 39 | 0.217 | 0.968 | 39 | 0.703 | ||
| Pretest of experimental group | 0.093 | 39 | 0.217 | 0.968 | 39 | 0.427 | ||
| Name | Pair difference | T-Value | Df | Sig(Double side) | ||||
| MD | SD | SE | Confidence interval | |||||
| Min | Max | |||||||
| Equalization | 0.092 | 11.977 | 2.179 | -4.636 | 4.316 | -0.068 | 39 | 0.935 |
| Inequality | 0.089 | 11.968 | 2.175 | -4.635 | 4.312 | |||
Post-test data analysis
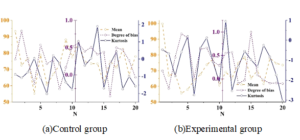
In the same way as analyzing the pre-test, in order to observe the obvious difference between the post-test scores of the two groups of students, it is necessary to carry out the test of difference (T-test) between the post-test scores of the two groups of students. Through the software analysis, the results of posttest data analysis of English achievement are shown in Figure 4. The data present that the mean scores of the experimental group and the control group are 72.88 and 66.85 respectively, reflecting the gap. The skewness values are 0.177 and 0.158, which are positively skewed, in addition, the kurtosis values of the control group and the experimental group are -0.564 and -0.809, respectively, which indicates that the simulation test is slightly difficult, and the difficulty is more or less the same for the two groups of students.
Difference detection
Carrying out the English achievement variability test, which is analyzed by the software, the results of the variability test are shown in Table 2, and it can be seen that the Sig values of the experimental group and the control group under the Kolmogorov-Smirnov columns are 0.176 and 0.217, both of which are greater than 0.05, which shows that the achievements of the two groups are basically normally distributed. Moreover, the normal distribution of the experimental group is closer to the normal curve, which can also be proved by the kurtosis value in the descriptive analysis, and the Sig (double-test) value is 0.004, which is less than 0.05. It can be seen that there is a significant difference between the post-test scores of the experimental group and the control group, and compared with the traditional English teaching mode, the English communication and interactive teaching mode integrating cognitive knowledge map proposed in this paper has more significant effects on the English language scores of the students. Achievement is more significant.
| Name | Kolmogorov-Smirnov | Shapiro-Wilk | ||||||
|---|---|---|---|---|---|---|---|---|
| Statistic | Df | Sig | Statistic | Df | Sig | |||
| Posttest of control group | 0.127 | 39 | 0.176 | 0.966 | 39 | 0.528 | ||
| Posttest of experimental group | 0.078 | 39 | 0.217 | 0.969 | 39 | 0.714 | ||
| Name | Pair difference | T-Value | Df | Sig(Double side) | ||||
| MD | SD | SE | Confidence interval | |||||
| Min | Max | |||||||
| Equalization | 6.032 | 3.376 | 0.608 | 4.835 | 7.388 | 9.928 | 39 | 0.004 |
| Inequality | 6.028 | 3.376 | 0.604 | 4.833 | 7.386 | |||
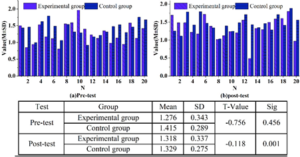
The pre and post-test analysis of students’ English expression complexity is shown in Figure 5.In the pre-test the complexity level of the control group is 1.276 but the control group’s is only 1.415.In the pre-test the t-value of the experimental group and the control group is -0.756.The level of significance is P=0.459\(\mathrm{>}\)0.05.So it can be seen that in the pre-test there is no significant difference between the experimental group and the control group. In the posttest, the complexity level of the experimental group is 1.318 and that of the control group is 1.329, in the posttest P=0.001\(\mathrm{<}\)1, after one year of interference with a large amount of comprehensible input there is no difference in the complexity level of the experimental group. According to these data, after one year’s intervention with a large amount of comprehensible input, the experimental group and the control group are significantly different in terms of the complexity of students’ English expressions. That is to say that in this university, in an authentic English interactive communication environment, the complexity of the students who received a large amount of comprehensible input was indeed the same as that of the students who relatively did not receive a large amount of comprehensible input.
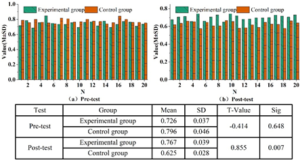
The results of the pre and post-test of students’ English expression fluency are shown in Figure 6, which shows that the fluency level of English expression of the experimental group is 0.726 and that of the control group is 0.796, but after analyzing the results by statistical software, we can conclude that the T-value of the experimental group and the control group is -0.414 in the pre-test.The level of significance is P=0.648\(\mathrm{>}\)0.05.Therefore we can conclude that there is no difference in the accuracy level between the experimental group and the control group in the pre-test of the fluency of the students’ English expression. Fluency pre-test there is no difference in the accuracy level between the experimental and control groups. In the posttest of students’ English fluency, the value of the experimental group is 0.767 and the value of the control group is 0.625 with a t-value of 0.855, p=0.007\(\mathrm{>}\)0.05. Based on the results of the pre and posttest analysis of students’ English fluency, after one year’s interference with a large amount of comprehensible inputs, the experimental group’s and the control group’s results of the posttest of students’ English fluency are significant, i.e., it indicates that the integration of Cognitive Knowledge Mapping of English Communication Interactive Teaching Model promotes the improvement of students’ English expression ability.
With the advancement of the new curriculum reform work, the modern education concept tends to be more and more humanized and humanistic, which requires teachers to design various teaching activities with students as the main body. This paper proposes a communicative and interactive teaching mode of English in colleges and universities under the theory of cognitive knowledge mapping, and uses SPSS data analysis software to empirically analyze its teaching mode. The research results are shown as follows:
In the pre- and post-test analysis of college English scores, the average scores of the experimental group and the control group are 72.88 and 66.85 respectively, reflecting the gap. The skewness values are 0.177 and 0.158 respectively, which are positively skewed, and the Sig (double-test) value of the English post-test scores of the experimental group and the control group is 0.004, which is less than 0.05, indicating that the teaching mode proposed in this paper has a more obvious effect on the improvement of students’ English scores compared with the traditional teaching mode.
Through the analysis of students’ English expression ability, in the post-test of students’ English expression fluency, the value of the experimental group is 0.767, the value of the control group is 0.625 and the T-value is 0.855, P=0.007\(\mathrm{>}\)0.05, which indicates that there is a significant difference in the improvement of students’ English expression ability between the interactive English communication teaching mode integrating cognitive knowledge mapping and the traditional English teaching mode.
Research on Professional Development Paths of Foreign Language Teachers in Higher Vocational Colleges under the Background of Artificial Intelligence, Foreign Language Teaching Reform and Research Project under the New Standard of Vocational Education in 2023 of the Advisory Committee of Foreign Language Teaching in Vocational Education, Ministry of Education, P.R. China (Project No. WYJZW-2023SD0016).




