Association rule mining is a well-established rule-based data mining algorithm that has been widely used to uncover association relationships of interest in data [1,2].
Labor education and ideological and political education in the new era are both indispensable components of China’s higher education talent training system [3,4], and it is of great significance to integrate them into the whole process of college student training and carry out in-depth integration and collaborative education to fully implement the education policy of “simultaneous development of five educations” and jointly implement the fundamental task of cultivating people with virtue [5-7]. Although labor education and ideological and political education are different in status and role, they are intrinsically related in educational objectives, educational content and educational methods and approaches [8,9]. Therefore, labor education and ideological and political education rely on labor education class and ideological and political theory class respectively, based on the curriculum construction of two-way penetration, synergistic education [10,11].
With the continuous promotion of the education system, quality education has been further emphasized, and the implementation of the “five education” integration has become an important educational task for the majority of teachers [12]. Labor education as a major form of improving the level of students’ labor ability and labor awareness, is conducive to promoting the healthy development of students’ physical and mental health, and its content and ideological and political courses have a high degree of overlap [13,14], and need to take a reasonable way for teachers of ideology and politics to take the labor education and ideological and political theory class practice teaching integration [15]. The guidance for labor education in colleges and universities clearly states that colleges and universities must adjust the operation mechanism of labor education, build a diversified mode of labor education, and take the cultivation of students to become “quasi-laborers” as the educational orientation, so as to improve the effectiveness of labor education [16,17]. From the point of view of the curriculum structure of ideological and political courses, the practical teaching of ideological and political theory courses is closely related to various fields, with rich teaching content, and presenting the characteristics of many points, long lines and wide surfaces, and the integration of labor education into the practical teaching of ideological and political theory courses can effectively expand the content and scope of education, and realize the further innovation of the practical teaching of ideological and political theory courses [18,19].
This paper proposes the M-ISODATA algorithm after improving the selection method of the initial clustering center in the ISODATA clustering algorithm, setting the clustering evaluation function to optimize the iterative convergence process of the algorithm, and using the DBI index to determine the validity of the clustering results, so as to improve the clustering algorithm’s efficiency and accuracy in data mining. The improved algorithm is used to cluster the data related to students’ ideological education and labor ability cultivation. Meanwhile, this paper adds correlation coefficients on the basis of Top-K association rule mining algorithm, mines the association rules with the highest support in the dataset through the process of SAVE and Expand, calculates the degree of enhancement between the sets of association rules, and obtains the strong association rules between Civic and Political Education and Labor Ability Cultivation Mechanism. Finally, taking school Z as an example, after clustering analysis of the scores of both students’ civic and political education and labor ability cultivation, the correlation between the two is analyzed using the association rule mining algorithm. And combined with the analysis, it proposes an innovative education model for the integration of Civic and Political Education and Labor Ability Cultivation Mechanism, which provides reference for the development of school education work.
Compared with the k-means algorithm, the division-based ISODATA algorithm can optimize the clustering effect on the basis of the initial clustering by constant splitting and merging, etc., and automatically adjust the category center and the number of categories. And because the initial clustering center of ISODATA clustering method is arbitrarily selected, which brings great chance to the clustering results. If there are more noise points in the data, the influence of the initial clustering center on the clustering effect is more obvious. In this paper, in view of the shortcomings of the ISODATA algorithm mentioned above, and considering that there should be more data points around the clustering center in the dataset of students’ civic education and labor ability cultivation and that the distance between the clustering center and the other clustering centers should be larger, we propose a density-based improvement algorithm to select the initial clustering center according to the principle of maximum local density and the principle of distance from the points with high local density. Meanwhile, the algorithm can effectively deal with noise points, and the related definitions are as follows.
Let there be a student data set \(D=\left\{x_{1} ,x_{2} ,\cdots ,x_{m} \right\}\) with \(n\) attributes for each sample, i.e., \(x_{i} =\left(x_{i1} ,x_{i2} ,\cdots ,x_{in} \right)\), \(i=1,2,\cdots ,m\).
Definition 1. The distance between any two points \(x_{i}\) and \(x_{j}\) is: \[\label{GrindEQ__1_} d\left(x_{i} ,x_{j} \right)=\sqrt{\sum _{s=1}^{n}\left(x_{is} -x_{js} \right)^{2} }.\tag{1}\]
Definition 2. The average distance between sample points in the entire data set is: \[\label{GrindEQ__2_} d_{avg} =\frac{2}{m(m-1)} \times \sum _{1\le i<j\le m}d \left(x_{i} ,x_{j} \right) .\tag{2}\]
Definition 3. The density of sample point \(x_{i}\) is defined as: \[\label{GrindEQ__3_} \rho \left(x_{i} \right)=\sum _{j=1}^{m}u \left(d_{avg} -d\left(x_{i} ,x_{j} \right)\right).\tag{3}\] That is, the sum of the number of other data points contained in a circle with \(x_{i}\) as the center and \(d_{avg}\) as the radius, where \(u\left(x\right)=\left\{\begin{array}{l} {1,x\ge 0} \\ {0,x<0} \end{array}\right.\).
Definition 4. The mean of the sample density is defined as: \[\label{GrindEQ__4_} \rho _{avg} =\frac{1}{m} \sum _{i=1}^{m}\rho \left(x_{i} \right).\tag{4}\]
Definition 5. The minimum distance between sample point \(x_{i}\) and other higher density points is: \[\label{GrindEQ__5_} \delta _{i} ={\mathop{\min }\limits_{\rho \left(x_{j} \right)>\rho \left(x_{j} \right),1\le j\le m}} \left(d\left(x_{i} ,x_{j} \right)\right).\tag{5}\] If there exists no \(x_{j}\) such that \(\rho \left(x_{j} \right)>\rho \left(x_{i} \right)\), then: \[\label{GrindEQ__6_} \delta _{i} ={\mathop{\min }\limits_{1\le j\le m}} \left(d\left(x_{i} ,x_{j} \right)\right).\tag{6}\]
Definition 6. A sample point \(x_{i}\) is said to be an anomaly if it satisfies \(\rho \left(x_{i} \right)<\alpha \times \rho _{mg}\), \(0<\alpha <1\), \(\delta _{i} >\beta \times \max _{1\le j\le m} \left(\delta _{j} \right)\), \(0<\beta <1\).
Furthermore, the ISODATA algorithm is a cyclic iterative method that stops converging when the number of iterations is reached. However, deciding the end of the algorithm based only on the number of iterations may lead to insufficient split-merge conditions and imperfect results. In this paper, we set a clustering evaluation function corresponding to each iteration, and the iterative process is considered to converge when the function takes a value that no longer changes. It can judge both the effectiveness of clustering and the control parameter taking value without a priori knowledge.
Definition 7. Consider the cluster division of the clustering results of students’ Civic and Political Education and Labor Ability Cultivation \(C=\left\{C_{1} ,C_{2} ,\cdots ,C_{k} \right\}\), define \[\label{GrindEQ__7_} avg\left(C\right)=\frac{2}{\left|C\right|\left(\left|C\right|-1\right)} \sum _{1\le i<j\le \left|C\right|}dist \left(x_{i} ,x_{j} \right).\tag{7}\] \[\label{GrindEQ__8_} d_{cen} \left(C_{i} ,C_{j} \right)=dist\left(c_{i} ,c_{j} \right) .\tag{8}\] \[\label{GrindEQ__9_} DBI=\frac{1}{k} \sum _{i=1}^{k}\max _{j=i} \left(\frac{avg\left(C_{i} \right)+avg\left(C_{j} \right)}{d_{con} \left(C_{i} ,C_{j} \right)} \right).\tag{9}\]
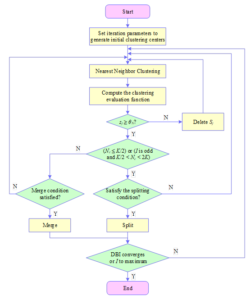
The DBI index represents the average value of the intraclass distance between any two classes divided by the distance between the two cluster centers to find the maximum value. Obviously, the smaller the value of DBI index, the better. The specific process of the improved M-ISODATA algorithm is shown in Figure 1. Aiming at the large number of datasets as well as the characteristics of high feature dimensions, the M-ISODATA algorithm is used to adapt to the situation of high-dimensional data, and the M-ISODATA algorithm can refine the dataset of students’ civic education and labor ability cultivation into multiple small datasets, each of which represents a class of sets with the same feature vectors, and the idea of classification mining is used to improve the accuracy of the mining results and the efficiency through the idea of classification mining.
Association rule mining algorithm is a mining algorithm to discover frequent itemsets, which is an important topic in data mining, and its main functional feature is to find the hidden relationships between specific data sets and discover valuable information from them. The process of association rule mining is roughly divided into two stages, the first part needs to find out the frequent itemsets in the original dataset. The second part then mines association rules from these frequent itemsets by pruning and sorting.
At this stage, the common association rule mining algorithms are mainly through the entire data set to mine the corresponding association rules, when the data set is very large, often produces a huge amount of redundant data and similar association rule mining results, which will also lead to association mining algorithms to mine the results of the final results are not accurate. For example, the Apriori algorithm finds frequent itemsets by frequently accessing the database, and in the face of massive datasets, this frequent access to the database with the expansion of the dataset leads to a reduction in the efficiency of the algorithm. And although the FP-growth algorithm avoids the situation of accessing the database a lot by building an FP-tree, a large amount of data will also cause the FP-tree to be too large. Therefore, this will greatly affect the overall efficiency of the algorithm and the accuracy of the mining results, and it can not be well adapted to the characteristics of the course big data.Top-K is an association rule mining algorithm designed by Fournier-Viger, compared with traditional association rule mining algorithms, the algorithm’s advantage lies in the fact that it can be user-specified by the number of rules to be generated \(K\), avoiding the generation of too many rules, and therefore the efficiency is better than the traditional association rule mining algorithms. Therefore the efficiency is higher than the traditional association rule mining algorithm.
In this paper, we improve the Top-K association rule mining algorithm by adding correlation coefficients to the Top-K algorithm to improve the accuracy of the algorithm and further improve the efficiency of the algorithm. In the process of mining the association rules of students’ civic education and labor ability development, through practice, it is found that the minimum support is more difficult to design than the minimum confidence because the minimum support depends on the database characteristics that are unlikely to be known by most of the users, whereas the minimum confidence represents the expected confidence that the users really want in the association rules, and it is usually easy to judge. Therefore, the goal of this algorithm is to mine the Top-K rules with the highest support for students’ civic education and labor capacity development while satisfying the expected confidence level. The flow of the algorithm is as follows.
Scan the database of students’ Civic Education and Labor Capacity Development. Scan each single itemset and then generate all itemsets of 1*1 size and calculate their support and confidence, for each valid rule \(\left\{i\right\}->\left\{j\right\}\) or \(\left\{j\right\}->\left\{i\right\}\) call the procedure SAVE to deposit the rule into \(L\). In addition, each valid 1*1 rule is deposited into \(R\) to be considered for later expansion and the flag EXPAND LR is marked true. then the rule \(r\) with the highest support in \(R\) is recursively selected, making \(\sup \left(r\right)\ge \min \sup\) and expanding it, and the loop terminates when there are no more rules with support higher than the min sup in \(R\). For each rule, the flag EXPAND-LR indicates whether the rule is expanded by calling the procedures EXPAND-L and EXPAND-R or by calling EXPAND-L only.
SAVE process. Its function is to raise the minsup and update the list \(L\) when a new valid rule is found for \(r\). The first step is to add rule \(r\) to \(L\). If \(L\) contains more than \(k\) rules and the support is higher than the minsup, the rules with support less than or equal to the minsup can be deleted from \(L\), until only \(k\) rules are kept, and finally the one with the smallest support of the rule \(r\) in \(L\) will be set as the minsup.
Expand process. It takes rule \(I\to J\) as to be expanded, scans \(R\), and finds the rule \(r\) with the highest support in \(R\) as the expansion object. The algorithm scans each itemset \(tid\) from tids \((I\cap J)\). where \(tids\left(A\cap B\right)\) denotes the set of all itemsets that contain both \(A\) and \(B\) items. During this scanning process, for each item \(C\) appearing in each itemset, \(tid\) is added to \(tids\left(I\to J\bigcup \left\{c\right\}\right)\) if all \(C\) are greater in lexical order than all the items in \(j\). Once the scanning is complete, for each item \(c\), the rule \(I\to J\bigcup \left\{c\right\}\) is considered frequent if \({\left|tids\left(I\to J\bigcup \left\{c\right\}\right)\right|\mathord{\left/ {\vphantom {\left|tids\left(I\to J\bigcup \left\{c\right\}\right)\right| \left|T\right|\ge \min \sup }} \right. } \left|T\right|\ge \min \sup }\), and is added to the set \(R\) for later consideration for expansion. Finally, the confidence level of each frequent rule \(I\to J\bigcup \left\{c\right\}\) for student Civic Education and Labor Competency Development is calculated to determine if the rule is valid by dividing \(\left|tids\left(I\to J\cup \left\{c\right\}\right)\right|\) by \(tids\left(I\right)\), and if \(I\to J\bigcup \left\{c\right\}\) the confidence level is not less than minconf, the rule is valid and the procedure SAVE is called to add the rule to the list \(L\) of current Top-K rules.
The K values have a great effect on the improvement of the algorithm of the algorithm, which has been studied to find that the accuracy rate of the number of the method of the algorithm is 0.762,0.815 and 0.793, so the value of the algorithm is better.
The original Top-K association rule mining algorithm is based on the traditional “support-confidence” model, but the traditional “support-confidence” model can only find out the strong association rules in the frequent items set, but not the effective strong association rules in the strong association rules of the students’ ideological and political education and the cultivation of labor ability. However, the traditional “support-confidence” model can only find the strong correlation rules in the frequent items, but not the effective strong correlation rules among the strong correlation rules of students’ ideological education and labor ability cultivation. For rule \(A\to B\) or \(B\to A\), the correlation coefficient is defined as: \[\label{GrindEQ__10_} \text{lift}\left(A,B\right)=\frac{p\left(A\cap B\right)}{P\left(A\right)*p\left(B\right)} .\tag{10}\] The correlation coefficient lift reflects how much the “occurrence of item set \(A\)” affects the probability of occurrence of item set \(B\). In practice, both positive and negative correlations have many problems that deserve close attention. When lift is greater than 1, it means that the former term has a positive promotion effect on the latter term, and the larger the value, the greater the promotion effect. On the contrary, it is an inhibitory effect, while when lift is 1, it can be seen from the formula that the occurrence of \(X\) does not have any effect on the occurrence of \(Y\), so do not consider the case of lift is 1. \[\label{GrindEQ__11_} \text{lift}\left(A\to B\right)\left\{\begin{array}{l} {>1,\; \text{Positive correlation}} \\ {=1,\; \text{Independent}} \\ {<1,\; \text{Negative correlation}} \end{array}\right.\tag{11}\]
Therefore, in this paper, the correlation coefficient can only be used to determine the correlation between a set of items on the basis of support and confidence, and correlation cannot be equated with causality, so the correlation coefficients for the two rules \(A\to B\) and \(B\to A\) are the same: \[\label{GrindEQ__12_} \begin{array}{rcl} {\text{lift}\left(A,B\right)} & {=} & {\frac{p\left(A\cap B\right)}{p\left(A\right)*p\left(B\right)} =\frac{p\left(A\right)*p\left(B\left|A\right. \right)}{p\left(A\right)*p\left(B\right)} =\frac{p\left(B\left|A\right. \right)}{p\left(B\right)} } \\ {} & {=} & {\frac{\text{confidence}\left(A\to B\right)}{\text{support}\left(B\right)} =\frac{\text{confidence}\left(B\to A\right)}{\text{support}(A)} } .\end{array}\tag{12}\]
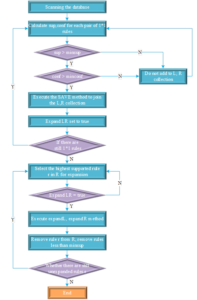
The specific flow of the improved Top-K association rule mining algorithm is shown in Figure 2. Rule pruning is very important for the algorithm to improve efficiency, reasonable pruning off the algorithm in the process of generating overfitting or redundant rules can also make the algorithm to reduce the amount of computation, and at the same time improve the overall accuracy. The Top-K association rule mining algorithm used in this paper is based on the framework of “support – confidence” by pruning the correlation coefficient to improve the efficiency of the algorithm for the analysis of the association rules between the students’ ideological and political education and the cultivation of labor ability.
To apply the association rule mining technology in the mechanism of students’ ideological education and labor ability cultivation, the prerequisite is that a huge amount of data must have been accumulated and the format of these data should meet the requirements of mining, in which the collection and preprocessing of the data of the students’ ideological education and labor ability cultivation should be completed before the association rule mining is carried out. In this paper, we take 300 students in school Z as an example to mine the association rules between their ideological and political education and labor ability cultivation. The analysis data of students’ civic and political education and labor ability level in the teaching system are collected as the information for the association rule analysis, and the initial information collected is stored in a data table, which corresponds to each student to store a data record, each data record includes the student number, name, and the average score of each scoring item, and finally the improved M-ISODATA clustering algorithm is used to cluster the students’ civic and political education and labor ability data for cluster analysis.
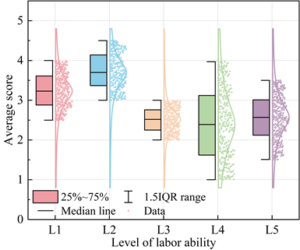
The results of the level of students’ labor ability cultivation in School Z obtained by the cluster analysis of M-ISODATA algorithm are shown in Figure 3, in which L1-L5 represent the scores of students’ concept of labor, knowledge of labor, ability to work, labor habits and quality of labor, respectively. The median line in the figure can reflect the average score of students under the index, and the distribution of normal curve can show the degree of aggregation of scores of each index under the cultivation of students’ labor ability. From the perspective of the various levels of students’ labor ability cultivation, only the average scores of the two levels of labor concept (3.23 points) and labor knowledge (3.74 points) are higher than 3 points, but not much higher, which indicates that in the cultivation of students’ labor ability, the cultivation of labor concept and labor knowledge has just reached the medium level and still needs further improvement. The average score of students in the aspect of labor ability is only 2.51, which indicates that the mechanism of cultivating labor ability in school Z needs to be improved. And the score range of labor habit is in 1-5 points, and there is a big gap between the scores of 300 students in labor habit, which shows that the school’s mechanism of cultivating students’ labor habit is very lack of. The results indicate that there is a lot of room for improvement in labor ability, labor habit and labor quality of the students in this school, which provides an important prerequisite for the subsequent research on association rules.
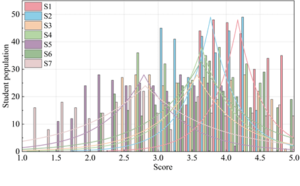
The results obtained from the cluster analysis of the scores of 300 students in various aspects of Civic and Political Education are shown in Figure 4. Civic and political education focuses on students, and it is important to take the growth and development of students as the criterion to analyze the learning effect of students in the seven aspects of Civic and political knowledge (S1), humanistic literacy (S2), social responsibility (S3), environmental ethics and morality (S4), global awareness (S5), life values (S6) and self-management ability (S7). In terms of the mastery of Civic and Political Knowledge, the average score of students is higher at 4.21, which indicates that students have a better mastery of Civic and Political Knowledge, and are able to form a correct worldview, life view and values while mastering the knowledge. The average scores of humanistic literacy, social responsibility, environmental ethics and life values in Civic and Political Education are all between 3.5-3.8, which is in the middle level. As for global awareness and self-management, the average score of students was below 3, and it was found that the scores of different students in self-management varied greatly.
In this section, based on the score data of students’ civic and political education and labor ability cultivation obtained from the above clustering analysis, the data are mined and analyzed by using the improved Top-K association rule to obtain the association rules that exist between students’ civic and political education and labor ability cultivation. A total of 388 association rules are obtained at a support level of 5% and a confidence level of 50%. The previously proposed lifting degree method is then utilized to filter the generated large number of rules. However, considering that one method, the lifting degree, is susceptible to the influence of zero things (things that do not contain any of the examined itemsets), it is necessary to carry out the cosine metrics of itemsets A and B first in order to eliminate the influence of zero things: \[\label{GrindEQ__13_} \cos (A,B)=\frac{P(A\cup B)}{\sqrt{P(A)P(B)} }.\tag{13}\]
Therefore, the cosine analysis was performed first, and when the results showed a weak positive/negative correlation (with a value of around 0.5), the degree of enhancement was calculated to help get a more complete description. The meaningful strong correlation rules between students’ civic education and labor capacity development obtained from the analysis are shown in Table 1. Rule 1 is P (S1 \(\Rightarrow\)L2) = 0.12, cos = 0.52, lift = 3.51, and this association rule is meaningful, indicating that 12% of students’ Civic and Political Education scores on Civic and Political Knowledge have a strong correlation with their labor knowledge scores on Labor Competency Development. The stronger a student’s ability to master Civics knowledge, then there is an 80% probability that his labor knowledge ability is also stronger, which shows the implied relationship between these two items, and improving a student’s ability to master Civics knowledge will improve his labor knowledge score in labor ability development. Rule 2 is a strong association rule between social responsibility (S3) and environmental ethics (S4) and labor concept (L1), which has a cosine value of 0.51 and an enhancement degree of 4.59, indicating that the association rule is meaningful. Students with a strong sense of social responsibility and environmental ethics are able to be helpful in their daily lives, actively participate in public welfare activities, and understand the relationship between human beings and society in a harmonious symbiosis, which in turn positively affects the formation of labor concept. Therefore, students with a stronger sense of social responsibility and environmental ethics must also have a stronger labor concept. The confidence level of Rule 3 is 100%, which indicates that the higher the students’ scores on humanistic qualities and life values in Civic and Political Education, the higher their scores on labor quality.
| Rule number | Rule content | Support | Confidence | Cos | Lift |
|---|---|---|---|---|---|
| 1 | S1\(\Rightarrow\)L2 | 12% | 80% | 0.52 | 3.51 |
| 2 | S3, S4\(\Rightarrow\)L1 | 8% | 100% | 0.51 | 4.59 |
| 3 | S2, S6\(\Rightarrow\)L5 | 6% | 100% | 0.58 | 2.68 |
| 4 | S3, S7\(\Rightarrow\)L4 | 5% | 91% | 0.55 | 5.67 |
| 5 | S1, S7\(\Rightarrow\)L3 | 5% | 95% | 0.52 | 6.04 |
Changing the thresholds of support and confidence, a total of five association rules were analyzed at 7% support and 60% confidence, and the specific analysis results of the association rules are shown in Table 2. Rule 4 is P (S2, S6, S7 \(\Rightarrow\)L5) = 0.07, cos = 0.51, lift = 4.01, the association rule is meaningful. It indicates that the scores of humanistic qualities, life values and self-management skills of 7% of all students participating in the analysis can influence the level of labor quality in the development of labor competence. It is also found that the confidence level of the association rule reaches 92%, so it can be concluded that promoting the formation of students’ life values and improving their self-management ability in the school’s civic education can improve the level of students’ labor quality, so that the school’s mechanism of labor competence cultivation achieves good results.
| Rule number | Rule content | Support | Confidence | Cos | Lift |
|---|---|---|---|---|---|
| 1 | S1, S7\(\Rightarrow\)L3 | 14% | 71% | 0.54 | 2.69 |
| 2 | S3, S4\(\Rightarrow\)L1 | 7% | 100% | 0.57 | 3.24 |
| 3 | S7\(\Rightarrow\)L4 | 7% | 89% | 0.59 | 2.78 |
| 4 | S2, S6, S7\(\Rightarrow\)L5 | 7% | 92% | 0.51 | 4.01 |
| 5 | S1\(\Rightarrow\)S2 | 7% | 100% | 0.52 | 3.29 |
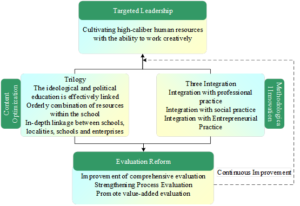
“Education must be combined with productive labor” is a basic feature of socialist school education. Cultivating high-quality talents with labor ability is a necessity to implement the education policy, and the cultivation of students’ labor ability is also an intrinsic meaning of ideological and political education. Based on the above analysis of the association rules between ideological and political education and the cultivation of labor ability, this paper proposes an innovative model for the integration and development of the two, and the specific path flow is shown in Figure 5. Schools should adhere to the concept of “integration of labor and creativity” in the process of civic education, integrate the cultivation of students’ labor ability into the objectives of talent cultivation in civic education, and lead the reform of civic education through the objectives throughout the whole process of talent cultivation. The teaching content of ideology and politics is optimized through the “triple linkage” path of effective linkage of the ideology and politics courses, orderly combination of resources on campus, and in-depth linkage between schools, localities, schools and enterprises. Through the “three integration” path of integrating the cultivation of students’ labor ability with the professional practice of Civics and Politics, with social practice, and with innovative practice, we innovate the mechanism of integrating Civics and Politics education with the cultivation of labor ability. At the same time, it promotes evaluation reform, takes the cultivation of labor ability as the core objective, focuses on comprehensive evaluation of Civic and Political Education, strengthens process evaluation, promotes value-added evaluation, follows the OBE education concept, and promotes continuous improvement. As a result, a four-pronged spiral cycle system has been formed, which includes the leading of the goal of labor ability cultivation, optimization of the content of civic and political education, innovation of teaching methods, and reform of teaching and evaluation, and it has been condensed into a unique model of innovation and integration of civic and political education and labor ability cultivation mechanism.
In order to explore the correlation between students’ civic education and the mechanism of labor competence development, this paper uses M-ISODATA clustering algorithm and Top-K association rule mining algorithm to statistically analyze the students’ data, and the results show that:
The average score of students in labor ability is only 2.51, which indicates that the mechanism of cultivating labor ability in school Z needs to be improved. And the score range of labor habit is at 1-5 points, and the gap between the scores of 300 students in labor habit is large, which indicates that the school’s mechanism of cultivating students’ labor habit is very deficient. The average scores of humanistic literacy, social responsibility, environmental ethics and life values in students’ civic education are all in the range of 3.5-3.8, which is in the middle level.
with a support level of 5% and a confidence level of 50% found that 12% of the students’ Civic Knowledge scores in Civic Education had a strong correlation with their Labor Knowledge scores in Labor Competency Development. Rule 3 (S2, S6 \(\Rightarrow\)L5) for a strong correlation between humanistic literacy, life values and students’ labor quality with a confidence level of 100% indicates that the higher students’ scores on humanistic literacy and life values in Civic and Political Education indicate that their labor quality scores are also higher. After the support and confidence level changed to 7% and 60%, it was found that 7% of students’ scores of humanistic literacy, life values and self-management ability can influence the level of labor quality in the cultivation of labor competence, and the confidence level of this association rule reached 92%.
Combining the above results, this paper puts forward the integration and innovation education model of “three integration”, “three association” and “three convergence” of the mechanism of civic education and labor ability cultivation to promote the joint development of students’ civic education and labor ability cultivation. This paper proposes the innovative education model of “three integration”, “three links” and “three convergence” to promote the joint development of students’ ideological education and labor ability cultivation.
The future of this article can be developed in the following directions:
the relationship between psychological characteristics and academic performance can be combined with the characteristics of students’ psychological characteristics. More focused on the academic and psychological problems that scientists may have.
The students’ course performance data sets can be characterized by a more subtle analysis of the students’ course further explore the technical characteristics of students and the future development of employment.
The work of the article can be added to the school’s education management department to achieve the personalized customs of the students the purpose of the note.




