Teaching mode is a favorable teaching tool to assist teachers in completing teaching tasks, and it belongs to part of the teaching process to help teachers better achieve teaching objectives and teaching tasks [1,2]. According to the teaching theory and teaching value orientation, teaching mode is divided into many kinds, and multimedia wisdom teaching mode is based on wisdom teaching as a theory, which is a new output result in the background of big data era, and also an innovative result of the continuous development of new curriculum teaching reform, multimedia wisdom teaching mode is a new teaching ecology that introduces modern information technology such as big data and internet to realize teaching in the teaching mode the teaching value orientation of this model is to realize the improvement of teaching quality by building a multimedia, intelligent, informative and digital teaching environment, and then improve students’ independent learning ability, their ability to solve learning problems, and continuously promote students’ wisdom production and development [3,4]. With the pace of development of the new curriculum reform, social development has put forward higher requirements and standards for education and teaching, and the traditional teaching mode has been unable to meet the teaching needs of higher vocational institutions, for this reason, the study of multimedia wisdom teaching mode in higher vocational education in the context of big data era is proposed to provide theoretical basis for the reform of higher vocational education mode [5,6].
After more than ten years of development, evolution and systematization, the theory of PE teaching has taken the shape of a disciplinary system [7]. It has some disciplinary terms, research paradigms and theoretical systems of its own, and occupies an important position in the disciplinary system of PE. The object of study of sport theory is sport, and sport is a subordinate concept of teaching [8]. Like other teaching, it is an educational process with attributes such as imparting knowledge and skills. With the continuous introduction of new concepts and methods of PE from abroad and the real needs of the country for reform in the field of education, research in the field of PE has been very active in China and many research results have been achieved [9,10]. The study [11] analyzed foreign sports research from 2004 to 2013, and it can be seen that most of the current sports research results in the world come from developed Western sports countries such as North America and Europe. Therefore, the author believes that at present, the sports of western countries represented by the United States are more successfully developed than our country, and their research results are more abundant and diverse, and there are many worthwhile experiences for the research of sports in China [12]. In the face of so many research results, we cannot help but think: what are the hot spots of research in the field of PE in China and the United States in recent years, what are the changes in research problems, what are the research results, and where the research trends will develop [13].
At present, domestic research on PE research is mostly focused on the analysis of individual basic elements in PE, while the overall research on PE research is slightly insufficient, mostly using content analysis and focusing on research hotspots, current situation analysis and trends, etc. However, the frontiers and hotspots in this research field and comparative research with foreign frontiers and hotspots are not abundant, so researchers need to spend a lot of time to understand the existing research results at home and abroad [14]. And in today’s era of rapid development of information technology, in the face of the vast amount of digital information, how to effectively mine and discover its characteristics and patterns has become one of the research priorities in the field of scientometrics. Therefore, based on the frontier analysis of PE research in China and the United States based on multimedia and big data technology, the author makes an intuitive analysis and comparison of PE in China and the United States, hoping to provide some references for future scholars in the field of PE.
In China, PE is still a young discipline, only a hundred years or so since its establishment [15]. Early research on PE in China (from about 1890 to 1904) mainly focused on the development of the form and content of PE, with a lack of attention to theoretical research [16]. With the development of the New Culture Movement and the introduction of new ideas, theories and methods from abroad, PE teaching research was developed to some extent, for example, “Research on PE” published by Chairman Mao Zedong in New Youth and “Research on School PE” written by Yun Daying. However, the research on PE in this period mostly stayed at the level of teaching contents and methods [17]. After the founding of New China until the end of the 1970s, the research on PE in China developed significantly, and a large number of theoretical textbooks and PE syllabuses were written and published, which greatly enriched the content of PE and effectively standardized PE [18]. After the reform and opening up, the practice of PE gradually increased, and the research results of pedagogy gradually penetrated into the field of PE research, and other works such as the first “Theory of PE Teaching” were published one after another, and PE research continued to develop [19]. In this century, with the “new curriculum reform” and “PE pedagogy” formally becoming an independent discipline, various research scholars in the field of PE have been interested in the combination of PE and lifelong PE, the integration of PE reform and the inheritance of traditional PE ideas, and the impact of the change of PE environment on PE. In order to clarify the current research on PE in China, it is important to consider the impact of the change of the teaching environment on PE, and the research on PE has begun to mature, which provides a guarantee for the construction of PE theory.
In order to clarify the general situation of the current research on PE in China, the author conducted a literature search in the General Publishing Library of Chinese Academic Journals, setting the subject as “PE”, the time as “1998 to unlimited”, and the matching method as “Exact”, and the search date was “November 30, 2017”. According to Bradford’s law of “stacking effect [20]” and the social science property of teaching, the source category was set as “CSSCI”, and 3117 documents were retrieved. The top 1,200 documents with high relevance were selected. The keywords of the 1200 documents were analyzed and counted by the analysis software of CNKI (China National Knowledge Infrastructure), and 23 keywords were obtained. According to the definition of PE, 10 keywords were obtained by removing meaningless keywords (e.g., PE, sports, etc.) and combining keywords with similar meanings (e.g., college students, college sports, college, college PE, etc.) (see Table 1). The subjects of PE are students and PE teachers, and the authenticity of PE teachers’ research is not reflected because the subject of PE is too broad. Therefore, by using the above search criteria, we searched for the topic “PE teachers” and retrieved a total of 1086 documents. Through further analysis of the literature, we found that although the frequency of universities was as high as 151 times, it was mostly combined with reform, teaching mode and other contents.
| Serial No | Keywords | Frequency |
|---|---|---|
| 1 | Colleges and universities (college students, college sports, general colleges and universities, college PE) | 151 |
| 2 | Reform (education reform, teaching reform) | 56 |
| 3 | Mode (PE teaching mode, teaching mode) | 48 |
| 4 | quality education | 17 |
| 5 | Students | 12 |
| 6 | PE Curriculum | 10 |
| 7 | PE Teachers | 9 |
| 8 | Teaching Objectives | 7 |
| 9 | Teaching Design | 5 |
| 10 | Teaching Methods | 3 |
From the domestic literature and related studies, although there have been some achievements in the historical development, review and evaluation of PE teaching research branches, there is still a slight lack of research combing the results of PE teaching research in China from the scientometrics perspective and information visualization perspective, especially the comparative analysis of PE teaching research in China and the United States, and the lack of the frontier and hotspots in the field of PE teaching research Therefore, this paper takes a quantitative analysis of Chinese and American PE research. Therefore, based on the analysis and comparison of the frontiers and hotspots of PE research in China and the United States, this paper introduces the methods of scientometrics into the field of PE from the perspective of combining qualitative and quantitative analysis, and with the help of CiteSpace software, an international advanced software in the field of scientometrics, to conduct an econometric analysis of PE research. The study is based on a combination of qualitative and quantitative analysis, introducing scientometric methods to the field of PE, and presenting the frontiers and hot issues of PE research in China, and conducting comparative analysis between China and the United States, so as to promote the further development of PE research.
The flow chart of the basic principle of the genetic algorithm is shown in Figure 1.
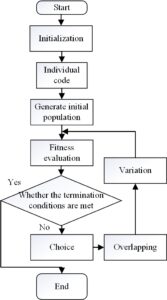
Genetic algorithm is an optimization method that follows the survival rule of “natural selection, survival of the fittest”. First, a random search is required to find a set of potential solutions that can solve the problem, that is, the initial population, and then evaluate the fitness of each potential solution. The higher the fitness, the greater the probability of the potential solution being selected, and then two A potential solution is crossed and mutated to obtain offspring individuals, and finally a new offspring population is obtained by continuous iteration. Although the genetic algorithm cannot guarantee that the final obtained solution must be the optimal solution, it does not need to worry about how to find the optimal solution. It only needs to remove some individuals with poor fitness in the iterative process.
Environmental modeling and population initialization are the preconditions for determining the performance of genetic algorithms. A good environmental modeling can truly present the real environment of rural industrial revitalization, and can accurately calculate the relationship between rural revitalization path selection and actual development. The relationship is conducive to the optimization of the rural industry revitalization path, and it is also conducive to the more diverse individuals in the initial population.
Environmental modeling is the foundation, and the commonly used environmental modeling methods include grid map method, linkage map modeling method and multifaceted model representation method. However, in order to facilitate the description of this paper, a uniform distribution of two-dimensional grid points is used in this paper, as shown in Figure 2.
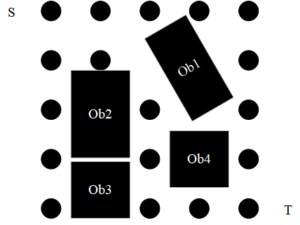
The available paths are then represented as follows:
\[\label{e1} \left\{\begin{array}{l} P=\left\{p_1, p_2, p_3, \ldots, p_n\right\} \\ p_1=S, p_n=T, p_i \cap O b_j=\varnothing \end{array} \quad(1 \leq i \leq n, 1 \leq j \leq n)\right.\tag{1}\]
In the Eq. (1), \({{p_i}}\) represents the \(P\) rd node of path \(i\) , and \(n\) represents the number of available path nodes. The path obtained based on the improved genetic algorithm under multiple constraints is represented as:
\[\label{e2} {P^*} = \left\{ {\left. {p_1^*,p_2^*,p_3^*,…,p_m^*} \right\},_{}^{}} \right.{P^*} \in P.\tag{2}\]
In the formula, \(m\) represents the number of paths obtained by the algorithm in this paper, and the path needs to satisfy
\[\label{e3} f({P^*}) = \min \left\{ {\left. {{f_1}(P),{f_2}(P),{f_3}(P),} \right\},} \right.\tag{3}\] where \({f_1}(P),{f_2}(P),{f_3}(P)\) is defined by Eq. (4), Eq. (5) and Eq. (6), respectively
Definition 1. The length index refers to the total length of the path, which can be expressed as:
\[\label{e4} {f_1}(P) = \sum\limits_{i = 1}^{n – 1} {|{p_i}} {p_{i + 1}}|,\tag{4}\] where \(|{p_i}{p_{i + 1}}|\) is the Euclidean distance from the path node \({p_i}\) to the path node \({p_{i + 1}}\). Finding the shortest path is one of the optimization objectives of the genetic algorithm under multiple constraints.
The other two optimization objectives are defined as follows:
Definition 2. The smoothness index refers to the sum of the angles of all adjacent vector line segments in the path, which can be expressed as:
\[\label{e5} {f_2}(P) = {C_1} \times S + \frac{1}{{{N_T}}}\sum\limits_{i = 2}^{{N_i} – 1} {} ,\left( {{p_i}{p_{i + 1}},{p_{i + 1}}{p_{i + 2}}} \right),\tag{5}\] where \(\theta ({p_i}{p_{i + 1}},{p_{i + 1}}{p_{i + 2}})\) is the angle between adjacent vector segments \({p_i}{p_{i + 1}}\)and \({p_{i + 1}}{p_{i + 2}}\),\({C_1}\) is a positive integer, \(s\) is the number of segments in a path, and \({N_i}\) is the number of points in the \(i\)th iteration path.
The population initialization method adopted by the traditional genetic algorithm is random. Many studies generate points by randomly scattering them in free space or by considering all points in a grid map. These methods have to consider unnecessary points for the optimal path in the path generation stage, which is computationally expensive. To this end, some scholars have proposed some improved methods.
The specific steps of SPS algorithm to generate the initial population are as follows.
The chromosome code and fitness function are the core elements that determine the performance of the genetic algorithm. A good chromosome code and fitness function can reduce the complexity of the performance of the genetic algorithm, and can select individuals with better fitness to inherit it to the next generation. It helps to further improve the performance of the algorithm.
In this paper, the rural industry revitalization works in the space of uniformly distributed two-dimensional grid points. Each point in the space has its own coordinates, which is exactly suitable for two-dimensional coding: \(({x_1},{y_1}) \to ({x_2},{y_2}) \to … \to ({x_n},{y_n})\) , \({x_i}\) and \({y_i}\) and are potential coordinates in the two-dimensional coordinates. The abscissa and ordinate of the path nodes, and the number and length of the path nodes are variable. This coding method can increase the precision and flexibility of the search. Figure 3 is an example of path encoding.

The fitness function is a function that measures the fitness of each individual in the population and is determined by the objective function. Once the initial population is formed, the genetic algorithm must determine the performance of each individual based on a fitness function that assigns each feasible solution a fitness value that reflects its quality. It is an important part of the evolution process of genetic algorithm, and proper selection of fitness function will make the search develop towards the optimal solution. The fitness function must consider some criteria, such as the length of the path, the degree of safety, and the smoothness, etc., because the genetic algorithm needs to use the value of the function to select individuals and reproduce offspring through crossover mutation, until the end of the algorithm to select the best of the final population. untie.
The fitness function in this paper needs to consider three criteria: path length, path smoothness and path safety. Among them, path length and path safety are taken as primary criteria, and path smoothness is taken as secondary criteria, and will be used as their objective functions.
This paper adopts the fitness value distribution method of SPEA2. When assigning fitness value to each individual, this method considers both the number that dominates the individual and the number that is dominated by the individual. The main process is as follows:
\[\label{e6} S(i) = \frac{t}{{N + 1}}.\tag{6}\]
Among them, \(i\) represents the individuals in \(P'\), \(t\) represents the number of individuals in \(P'\) and \(i\) dominates the number of individuals in \(P\) .
\[\label{e7} f(i) = 1 + \sum {S(j)},\tag{7}\] where \(j\) represents the individual who dominates \(P'\) in \(i\) , and \(S(j)\) is the fitness value of individual \(j\) in \(P'\) .
This paper makes a little improvement to the method: in the process of copying from set \(p\) to \(P'\), it is judged whether there are duplicate solutions, and if so, delete them, which can effectively prevent the premature convergence caused by the rapid reproduction of individuals with good fitness.
Genetic operators and termination conditions are the keys to determine the performance of genetic algorithms. Excellent genetic operators and termination conditions can not only speed up the convergence speed of the genetic algorithm, but also reduce the running time of the algorithm, find the optimal solution at a faster speed, and help to further improve the performance of the algorithm.
The genetic operators of traditional genetic algorithms include selection, crossover and mutation. The improved genetic algorithm proposed in this paper adds deletion operators, repair operators and smoothing operators on the basis of traditional genetic algorithms to improve the convergence speed of the algorithm and reduce the Run time, optimize the path of rural industry revitalization.
For the selection operator, this paper adopts the championship method for selection, that is, the individuals in the population are randomly grouped, and each group selects the individual with the best fitness value according to the fitness value of the individual to enter the sub-generation population, and iterates continuously until the sub-generation The population number reaches the preset population number. The elite retention strategy is adopted, and the individuals with the best fitness are directly copied to the offspring population according to a certain proportion without going through genetics.
For the crossover operator, this paper adopts the single-point crossover method, that is, randomly selects two individuals, finds the same point of the path and crosses it, so as to ensure the continuity of the path, as shown in the process of Figure 4, if more than one path has the same point, then Randomly select any one for path intersection. If there is no same point on the path, then randomly select two points from the two individuals to cross. If the path is not continuous after the intersection, the last point of the upper half and the lower half of the path are combined. The first point is used as the starting point and the target point, and is patched with the surrounding point set of the obstacle to make it a continuous path.
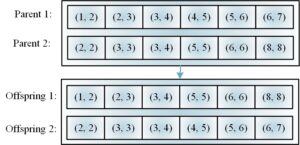
For the mutation operator, if it is a feasible path, the mutation probability is small, and the points on the path are adjusted within a small range; if it is an infeasible path, the mutation probability is large, so that the points located in the obstacle are adjusted in a large range.
For the deletion operator, before the deletion operator is not added, the situation shown in Figure 5(a) may occur, and more iterations are required to make the path approach smooth. Therefore, the deletion operator is added in this paper. If there is a situation as shown in Figure 5 in a path, after deleting \({p_i}\), \({p_i}\) the previous path point of \({p_{i – 1}}\) is connected with the next path point \({p_{i + 1}}\), which is a feasible path segment, then delete it, connecting and to generate a new path, as shown in Figure 5, thereby speeding up the convergence speed of the algorithm to a certain extent and reducing the running time of the algorithm.

For the repair operator, if a path segment intersects with an obstacle, as shown in Figure 6, the points around the generated obstacle can be connected in sequence, as shown in Figure 6.

For the smooth operator, it is mainly inspired by the particle swarm algorithm. Each coordinate point in the path of this paper is equivalent to the position of the particle in the particle swarm algorithm. The speed of the particle is calculated according to the coordinates of the coordinate point before and after, and the formula is updated according to the position. and velocity update formula to calculate new coordinate points to make the path smoother after many iterations. The process is shown in Figure 7 (where is the inertia weight, which represents the degree of influence of the speed at the previous moment on the current speed, and \({r_1}\) and \({r_2}\) are random numbers between 0 and 1).
In order to maintain the diversity of the population during the operation of the genetic algorithm and avoid falling into the local optimum, this paper adopts the niche method. The traditional genetic algorithm is prone to premature phenomenon, and the genetic algorithm runs serially in nature, and the evolution process is relatively slow. In order to avoid the above problems, this paper decomposes \(2M\) population individuals into \(M\) niches, each of which is composed of 2 similar population individuals. The similarity of populations is determined by the Hamming distance, and the smaller the Hamming distance is, the higher the similarity. Then, \(M\) niches are evolved and multiplied at the same time, and then 2 excellent individuals are selected in each niche to enter the next generation. Finally, individuals with high fitness in each niche are selected to form a new population for evolution and reproduction. The diversity of the population is maintained, and the running speed of the algorithm is accelerated to a certain extent.
In order to enable the improved genetic algorithm in this paper to find the optimal or sub-optimal path in a short time, this paper sets three termination conditions: first, the optimal individual fitness value obtained after multiple iterations satisfies the preset value The algorithm can be terminated when the threshold is reached; second, the overall fitness value of the population does not change much after many iterations, and the algorithm can be terminated; third, when the number of iterations of the algorithm reaches the preset algebra, the algorithm It can be terminated. This paper sets the iteration for 100 times.
In this paper, the support and importance of condition attributes to decision attributes are introduced into the genetic algorithm as heuristic information, and the algorithm flow of the IGA+RS algorithm is established as shown in Figure 7.
The IGA-RS algorithm needs to first calculate the support: according to the Eq. [e1]: calculate the attribute x according to the Eq. (2). The importance of \(\in c\) to the decision attribute set D is MMPC12(x).
This paper uses CiteSpace V (version 5.1.R8) to analyze the co-citation network knowledge graph of 946 documents from 2012 to 2016. Among them, Years Per Slice in Time Slicing is 1, Top N is 50, Visualization defaults to Cluster View-Static and Show Merged Network, and the threshold defaults to (2,2,20), (4,3,20), (4, 3, 20), running to get the document co-citation network graph, including 256 nodes and 699 connections. Based on the literature co-citation network map, the literature co-citation cluster knowledge map is obtained through clustering and cluster naming (proposed by Title), as shown in Figure 8. A total of 39 clusters were formed in the clustered knowledge graph of the frontiers of PE research in the United States. Among them, the 8 clusters with the largest area are #0, #1, #2, #3, #4, #5, #9 and #10, as shown in Table 2. These eight clusters reflect the major research fronts in the field of PE teaching research in the United States.
| (cluster number) | (size) | (outline) | (clustering keywords) |
| 0# | 39 | 0.941 | Practice based model |
| 1# | 34 | 0.902 | (physical activity items) |
| 2# | 32 | 0.765 | (Sports Courses) |
| 3# | 32 | 0.857 | (quantitative study) |
| 4# | 29 | 0.812 | Prospective cross cutting survey |
| 5# | 18 | 0.961 | Preservice Teacher Education |
| 9# | 6 | 0.973 | (role of teachers) |
| 10# | 6 | 0.969 | (self achievement goal) |
As shown in Figure 2, the cluster names of 11 clusters that reflect the main research frontiers in the field of PE teaching in the United States are: “#0: models-based practice”, “#1: physical activity program”, “#2: adventure-PE lesson”, “#3: quantitative findings”, “#4: prospective cross-domain investigation” cross-cutting survey)”, “#5: initial teacher education”, “#9: teachers support” and “#10: self-reported achievement goal”.
The main research front area 1: 39 cited literatures of the knowledge base contained in cluster #0, the year span is 2006-2015, among which there are 8 main literatures in the literature represented by the node, including PE teachers The professional development, the PE model, the reform of PE, the method of PE, and the cooperative learning in sports. From the titles of these 11 papers, it can be seen that the research topics of this cluster mainly focus on the practice-based PE teaching mode, the role of PE teachers, and the PE teaching mode, method and content. As a result of class naming, the research front of this cluster is dominated by practice-based models of PE, and also includes the role of PE teachers in education and public health, the role of PE in health and education, the effect of social learning on girls’ participation in sports, and the models of PE and methods .
The information function is shown in the decision table of Table 3.
| U | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | d |
| U1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| U2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 | 21 | 2 |
| U3 | 1 | 1 | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 2 |
| U4 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 3 |
| U5 | 1 | 2 | 2 | 2 | 2 | 1 | 3 | 2 | 2 | 2 |
| U6 | 2 | 2 | 2 | 1 | 2 | 1 | 3 | 2 | 3 | 1 |
| U7 | 1 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 |
| U8 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 1 |
| U9 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 2 | 2 |
| U10 | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 1 |
| U11 | 1 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 |
| U12 | 1 | 2 | 1 | 1 | 1 | 2 | 1 | 2 | 2 | 2 |
| U13 | 2 | 2 | 2 | 2 | 2 | 1 | 3 | 2 | 3 | 1 |
| U14 | 1 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 1 |
| U15 | 2 | 2 | 2 | 2 | 2 | 1 | 3 | 2 | 3 | 1 |
It is biased towards problem research, while the research on PE teaching methods in the United States is biased towards student health; starting from the basic concept of information system, this paper introduces the support and importance of conditional attributes to decision-making attributes as heuristic information into genetic algorithm, and proposes an IGA+ The RS algorithm is used for knowledge reduction. The experimental results show that the IGA+RS algorithm is an effective knowledge reduction method, which can further improve the efficiency of rough set knowledge reduction. It is fast and effective. In the next research work, it can be applied to the reduction of mass production data This will have certain guiding significance for the optimization of production operations.
There is no funding support for this study.




