s the main channel for the cultivation of college students’ “three views” and socialist core values, ideological and political education class is an important part of ideological and political education in colleges and universities [1, 2]. The high-speed development of network technology has a profound impact on the learning life, way of thinking and values of college students [3], and their thoughts show a strong trend of independence, equality, openness and personalization [4]. The traditional Civics class in colleges and universities is a package teaching, which is centered on teaching materials and focuses on knowledge instillation by teachers’ lectures, so that students are in the role of passive reception in the teaching process [5]. The communication between teachers of Civics and students is limited to the classroom, and students can only rely on their own efforts to understand and consolidate their knowledge, which seems to be a bit confusing and does not achieve the purpose of ideological and political education. In addition, students’ learning is more utilitarian, resulting in students only focusing on the examination results of the Civics and Political Science course, and can not really achieve knowledge understanding and action transformation [6–8]. Therefore, how to break the limitations of time and space of Civics class lectures, improve the utilization rate of extracurricular time, stimulate students’ interest in learning Civics courses, improve the teaching effect of Civics classes, and cultivate students’ logical thinking ability has become a hot issue in the reform of Civics classes [9–11].
With the development of China’s higher education from elitist education to mass education, teachers of Civics and Political Science courses have less and less time to contact with students outside the classroom, and students rely solely on their own efforts to consolidate and review their knowledge [12–14]. And such a way is more likely to result in insufficient understanding of the Civics and Political Science course, coupled with the fact that students’ learning carries a strong utilitarian mentality, which leads to students learning for the sake of exams in the Civics and Political Science course [15]. Therefore, how to make efficient use of extracurricular time, strengthen students’ tutoring of the Civics course, at the same time, deepen college students’ understanding of the knowledge of the Civics course, and cultivate students’ logical thinking ability has the necessity of [16], and strengthen the effect of the Civics course lectures has become another focus of thinking about the innovation of the Civics course teaching method in colleges and universities [17], and with the help of the current popular course network idea, we should build a network that can be used specifically for the study and communication of the Civics course in universities. With the current popular idea of course networkization, a network platform should be constructed which can be specially used for learning and communication of university Civic and Political courses [18, 19].
In this paper, firstly, a visual recognition system for students’ evaluation materials and answer results is designed by using deep learning computer vision technology. Based on CAT-SOOP system, a set of augmented learning based Civics auxiliary teaching system is designed. Secondly, by building a network diagram of Civics exercises and combining the concept of cut-set in complex networks, we search for the learning behaviors of learners in the process of answering questions. By organically combining the perception ability of deep learning with the decision-making ability of reinforcement learning, the reinforcement learning recommendation method is integrated into the learning process of students to realize the improvement of students’ persistent and long-term knowledge level and learning ability. Finally, the effectiveness of the assisted teaching system on Civics learning is explored by choosing the dataset of exercises and learners’ response records of five university Civics courses as the data source.
This chapter introduces the overall design of the auxiliary teaching system for college students’ Civics courses in the context of deep learning, starting with the requirement analysis, which briefly describes the requirements of the auxiliary teaching system for Civics courses in colleges and universities. Second is the overall system architecture, discussing the overall design ideas of the system. Finally, it is the design of each module, briefly describing the new functions added in the auxiliary teaching system for college civic and political courses, and the design of the interaction relationship between modules.
The auxiliary teaching system for the Civics course in colleges and universities to be designed in this paper needs to meet the following requirements:
The basic functions of the auxiliary teaching system, including user login, identity identification, course guide, exercises practice, and page design of the guide system.
It is time-consuming and laborious to manually enter students’ information and question results, so the OCR recognition module is needed to recognize the student handbook and students’ handwritten characters to import students’ information and question results.
In the design of Civics courses and exercises, students are provided with in-class exercises to consolidate their knowledge after learning the courses, as well as a general exercise mode for students to practice after class, and finally, a recommended exercise mode, where the system recommends topics to students according to their knowledge status, so that students can do the least amount of questions and get the greatest improvement in their abilities.
In the Civics Exercise Recommendation Module, firstly, we pre-train the reinforcement learning recommendation system offline, and then through the recommendation model interface, the system outputs the recommended topics for students according to their knowledge status.
The question types currently supported by this system are the Civics courses studied at the university level, including five courses: Overview of the Basic Principles of Marxism, Introduction to Mao Zedong Thought and Socialism with Chinese Characteristics, Essentials of Modern Chinese History, Foundation of Ideological and Moral Cultivation and Law, and Forms and Policies, and the main forms of the exercise questions are single-choice, multiple-choice, short-answer, and expository questions.
The architecture of the Civics Aided Teaching System designed in this paper is shown in Figure 1, the teaching aid system includes three parts, the front-end, the database, and the exercise push part, and they are introduced one by one below.
Front-end
This part consists of two parts, one of which is the existing browser-based student login and exercise page in CAT-SOOP. The other part is a newly designed and implemented function in this paper, the computer visual recognition module for offline student evaluation materials and answer results.
Database
This part is provided by CAT-SOOP, which is expanded in this paper to support the newly added features. Mainly, the user section has been enhanced to add support for student evaluations in the student handbook and enhancements to the student question history to support enhanced learning recommendation features.
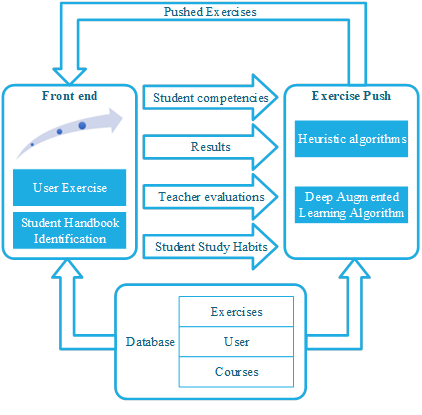
Recommended exercises
This part is a newly added function in this paper, which functions to recommend suitable Civics exercises according to students’ learning status, learning ability and learning characteristics. In the implementation of specific algorithms, heuristic and enhancement learning-based recommendation algorithms are designed and implemented.
In this paper, based on CAT-SOOP, an open-source online auxiliary teaching system of College X, we modify the existing modules and add new modules to realize the functions of computer visual recognition of in-depth offline student evaluation materials and adaptive exercise recommendation. The module diagram of the Civics Aided Teaching System and their interaction is shown in Figure 2, and the system consists of 8 modules. Among them, the newly added modules are OCR recognition module and recommendation module, modified course module, page module, exercise set module, scoring module, and user module, and the following mainly introduces the functions of the new modules, the way of realizing them, and the interrelationship between them.
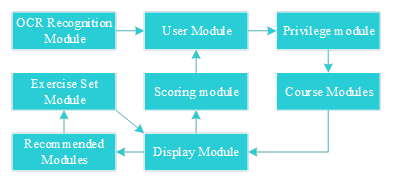
The OCR Recognition module is a new module added to enrich the information in the student variables with information from the student handbook and student handwritten characters. A new catalog handbook is added, and its specific functions are:
Pre-process the recorded images of student handbook and student handwritten characters by denoising, binarization, cutting, classification and other pre-processing processes to get the image style suitable for recognition.
The trained model is put on the server, and the pre-processed images are put into the corresponding API interface to recognize, and the server returns the results of the students’ evaluations and questions.
OCR recognition module is an API interface, users can input the whole picture and then get the result, which has better generality.
The OCR recognition module has the following relationships with other modules:
The recognition result of the student’s handbook will add the evaluation result given by the teacher to the student to the user variable, which makes the user’s parameter richer and helps us to analyze the next step.
The recognition result of the student’s handwritten characters will be fed into the recommendation model, which will be given to initialize the student’s knowledge state vector based on the student’s history of doing problems.
To provide a more efficient learning environment for students, the Civics Assisted Teaching System will recommend Civics exercises for students that are suitable for him according to his knowledge status, and we have added a new catalog, recom. Its specific functions are:
Recommending Civics exercises to students according to their knowledge status, which can dynamically monitor students’ Civics knowledge status, so that students can maximize the benefits of each topic they do, and reduce the time it takes for students to fully master the knowledge points.
The offline trained model is put into the Civics support system, which accepts students’ question data from the front-end page, updates students’ knowledge status, and finds the questions that can make students’ ability grow the fastest.
The relationship between the recommendation module and other modules is mainly to accept the data from the front-end page of the students’ questions, get the serial number of the students, as well as the time of the questions, the serial number of the questions, as well as the right and wrong of the questions. The recommendation algorithm based on reinforcement learning is utilized to recommend the Civics topics to the students and then the data is transmitted to the front-end page through the web service.
The construction of the network diagram of Civic and Political Studies is divided into two parts, one of which is the construction of the connecting edges of the topics under the same knowledge point, and the construction of the connecting edges under the knowledge points where there is a sequential relationship.
The network diagram of Civics exercises under the same knowledge point is shown in Figure 3, which can be represented as follows:
Under the same knowledge point \(A\), there are topics such as \(A_{1} ,A_{2} ,A_{3}\), each of which has its own difficulty attribute. For example, the difficulty attribute of topic \(A_{1}\) has difficulty \(A_{d}\) in knowledge point \(A\) and difficulty \(A_{1d}\) in knowledge point \(A\).
The predecessor and successor topics of a topic, and the weights of the edges between the topic and the predecessor and successor topics. For example, topic \(A_{6}\) has a successor topic \(A_{7}\), from \(A_{6}\) to point to this successor topic edge weight \(W_{A_{6} A_{7} }\), topic \(A_{6}\) has two predecessor topics \(\left(A_{4} ,A_{5} \right)\), from these two predecessor topics to point to the edge of \(A_{6}\) weight \(W_{A_{4} A_{6} } ,W_{A_{5} A_{6} }\).
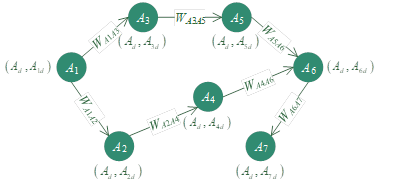
To answer a subsequent question, you need to answer the previous question correctly, and to answer a subsequent question incorrectly, you need to answer the previous question. For example, if you answer Question \(A_{1}\) correctly, you can proceed to Question \(A_{2} ,A_{3}\), and if you answer Question \(A_{6}\) incorrectly, you need to answer Question \(A_{4} ,A_{5}\).
A network diagram of the topics under the knowledge points where a sequential relationship exists is shown in Figure 4 and can represent the following:
Knowledge point \(A\) is followed by knowledge point \(B\), knowledge point \(A\) has topics such as \(A_{1} ,A_{2} ,A_{3}\), and knowledge point \(B\) has topics such as \(B_{1} ,B_{2} ,B_{3}\), each with its own difficulty attribute. For example, the difficulty attribute of topic \(A_{1}\) has difficulty \(A_{d}\) in knowledge point \(A\) and difficulty \(A_{1d} ,B_{1}\) in knowledge point \(A\). The difficulty attribute of topic \(A_{1d} ,B_{1}\) has difficulty \(B_{d}\) in knowledge point \(B\) and difficulty \(B_{1d}\) in knowledge point \(B\).

The predecessor and successor topics of a topic, and the weights of the edges between the topic and the predecessor and successor topics. For example, topic \(B_{3}\) has a successor topic \(B_{5}\), and the weight of the edge pointing to this successor topic from \(B_{3}\) is \(W_{B_{3} B_{5} }\). Topic \(B_{3}\) has two predecessors in knowledge point \(A\), topic \(\left(A_{3} ,A_{6} \right)\), and the weight of the edge pointing to \(B_{3}\) from these two predecessors is \(W_{A_{6} B_{3} } ,W_{A_{3} B_{3} }\).
To answer a subsequent question, you need to answer the previous question correctly, and to answer a subsequent question incorrectly, you need to answer the previous question. For example, if you answer Question \(A_{3}\) correctly, you can proceed to Question \(A_{6} ,B_{3}\), and if you answer Question \(A_{3}\) incorrectly, you need to answer Question \(A_{1} ,A_{2} ,A_{5}\).
The cut set is a collection of branches in the connectivity graph, if these branches are removed, the connectivity graph will be separated into two parts that are not connected to each other. There is a difference between a point cut set and an edge cut set, which is used here. The historical behavior of a particular learner with respect to the solution of an exercise is reflected in Figures \(G\) and \(T\) as a number of sets of successful and failed nodes and edges, noted as learner subgraph \(g\), and the learner network is shown in Figure 5. Through \(g\) one can obtain a graph \(g{\rm {'} }\) of topics to be selected in the topic network graph \(T\), and based on \(g{\rm {'} }\) one can obtain a cut-set of it, which will be the basis for locating the learner’s learning area. Thus, the problem of finding a learning zone for a particular learner’s answering behavior is transformed into the scientific problem of how to find a particular cut set in the network. The formal representation is: \[\label{GrindEQ__1_}\tag{1} f_{T} (B)\to C,\]
where, \(T\) is the topic network graph, \(C\) is the learner cut-set, \(B\) is the learner behavior record, and \(f_{T}\) refers to the function that obtains the cut-set \(C\) through the learner’s behavior, subject to the constraints of the learner’s subgraph \(g\).
The Q-Learning (Q-Learning) algorithm is an offline policy algorithm and a value-based reinforcement learning algorithm. Where Q is denoted as the \(Q\) value obtained by performing action \(A\) in state \(S\), also called \(Q-value\). The Q-Learning algorithm aims to maximize Reward by selecting the optimal action \(A\), i.e., the best action, in state \(S\) for maximum gain, with the ultimate goal of maximizing the \(Q\) value.
The Value update formula for the Q-Learning algorithm is: \[\label{GrindEQ__2_}\tag{2} \begin{array}{c} {Q(s,a)\leftarrow Q(s,a)+\alpha \left[R(s,a)+\gamma \max Q{'} \left(s{'} ,a{'} \right)-Q(s,a)\right]}, \\ {s\leftarrow s{'} } \end{array}\]
where \(\alpha\) is the learning rate, denoted as the update magnitude, \(R(s,a)\) is the immediate reward, \(\max Q{'} \left(s{'} ,a{'} \right)\) is the \(Q\) value obtained after choosing the action that maximizes the next state, \(\gamma \max Q{'} \left(s{'} ,a{'} \right)\) denotes the future long-term reward. \(R(s,a)+\gamma \max Q{'} \left(s{'} ,a{'} \right)\) is the true \(Q\) value of the action \(a_{t}\) taken in the current state \(s_{t}\), which consists of the immediate reward \(R\) and the long-term reward, \(Q(s,a)\) is the estimated \(Q\) value, and the difference between the actual \(Q\) value and the estimated \(Q\) value is denoted as \(\Delta Q(s,a)\). And when the difference tends to 0, \(Q(s,a)\) no longer changes and the whole tends to converge to a convergent state.
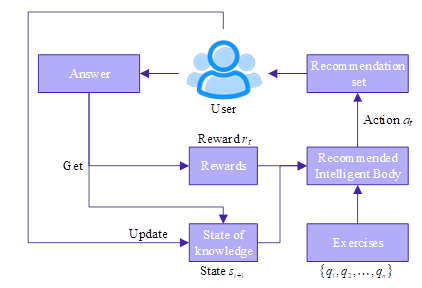
The elements in the reinforcement learning model are categorized into intelligences, states, actions, rewards, etc., respectively. In this paper, the recommendation scenario of Civics and Politics questions is based on reinforcement learning, so it is necessary to define the relevant reinforcement learning elements. In the next section, the elements of reinforcement learning are defined for the recommendation scenario in the personalized Civics and Politics exercise recommendation module. The flow of the Civics and Politics exercise recommendation model based on reinforcement learning is shown in Figure 6, specifically, each element of reinforcement learning will be defined separately:
Intelligent body
In this paper, a reinforcement learning-based Civics and Politics exercise recommendation model is constructed to be used as an intelligent body in the reinforcement learning recommendation scenario. The role of the intelligent body is to generate a new recommendation set as the user continues to explore the environment while learning with the Civics Aided Teaching System, taking actions to obtain rewards and updating the learner’s knowledge state.
State
The state of an intelligent body in the context of a recommendation scenario is represented as the discretized processed user knowledge state. The DKT deep knowledge tracking framework is utilized to train the student knowledge model based on the student’s history of doing problems, and the student knowledge state \(h_{t}\) is abstracted into the state \(S\) in reinforcement learning, denoted as \(S(t)=f(h_{t} )\), where \(h_{t}\) is the implicit representation of the student’s knowledge state, and \(f(\cdot )\) is the discretization processing function.
Action
The action of an intelligent body in the context of a recommendation scenario is represented as a set of to-be-recommended exercises \({\rm {\rm A}}_{T}\) generated according to the policy, which includes several exercises \(\left\{q_{1} ,q_{2} ,\ldots ,q_{n} \right\}\in {\rm {\rm A}}_{T}\), where \(n\) is usually 1 or 2, considering the action space problem.The value corresponding to the action \(Q(a)\) is represented by the expectation of the reward generated by the action, i.e: \[\label{GrindEQ__3_}\tag{3} Q(a)=E\left[R_{t} |{\rm {\rm A}}_{T} =a\right] .\]
The ultimate goal of the recommender intelligence is to take the optimal action so that it reaches a given state, similarly, the ultimate goal of the recommendation function is to recommend the most suitable exercise resources for the user to learn.
Reward
As the feedback given by the environment to the intelligent body for the current action, the reward for the intelligent body’s exploration in the recommended scenario environment is expressed as the integrated probability of answering the to-be-recommended exercise set in the current state of the user’s knowledge level. That is, the comprehensive mastery level of the current knowledge, denoted as \(\left\{pro\_ b_{1} ,pro\_ b_{2} ,\ldots ,pro\_ b_{m} \right\}\). Here, \(m=n\), after function mapping, is abstracted into the overall reward of the to-be-recommended exercise set, which can be denoted as: \[\label{GrindEQ__4_}\tag{4} R_{t} =f\sum _{i=1}^{m}pro\_ b_{i} ,\]
where \(f_{n} (\cdot )\) is a customized reward calculation function.
In this paper, we consider the user’s knowledge state level when defining rewards, and abstract the reward expression as the degree of comprehensive mastery of the current learner-recommended Civics exercise set. The reward function is represented as: \[\label{GrindEQ__5_}\tag{5} r_{t} =\frac{1}{N} \sum _{i=1}^{N}f \left(q_{i} \right) ,\]
where \(N\) is the number of exercises in the current recommendation set \(\left\{q_{1} ,q_{2} ,\ldots ,q_{n} \right\}\in Q_{n}\), and \(q_{i}\) is an exercise in the recommendation set. \(f(\cdot )\) is the probability of the current user answering the question correctly, which is calculated by the interaction of the user’s knowledge state matrix with the current exercise: \[\label{GrindEQ__6_}\tag{6} h_{t} =\tanh \left(W_{h_{q} } q_{t} +W_{hh} h_{t-i} +b_{h} \right),\] \[\label{GrindEQ__7_}\tag{7} y\left(q_{i} \right)=\sigma \left(W_{yh} h_{t} +b_{y} \right) ,\] \[\label{GrindEQ__8_}\tag{8} f\left(q_{i} \right)=probability\left(y\left(q_{i} \right)\right)=y\left(q_{i} \right) ,\]
where \(tanh\) is the \(tanh\) function, \(\sigma\) is the Sigmoid function, and \(W_{h} ,W_{yh}\) is the current user’s mastery state weight matrix for the currently learned knowledge point. \(h_{t}\) This matrix is obtained from the user’s personal knowledge state trained on the student’s history or data set, \(b_{h}\) is the bias of the hidden layer, \(W_{hh}\) is the recursive weight matrix. \(W_{yh}\) is the input weight matrix, and \(b_{y}\) is the bias of the output layer.
Meanwhile, the cumulative reward of the intelligences exploration is expressed as the sum of the discounted rewards as: \[\label{GrindEQ__9_}\tag{9} G_{t} =r_{t} +\sum _{n=1}^{N-n}\gamma ^{n} r_{t} ,\]
where \(r_{t}\) is the current immediate reward for the intelligence’s exploration, followed by a cumulative sum of future reward accumulations, \(\gamma\) is the discount factor, and \(\gamma \in [0,1]\).
When the user is learning, learning the current knowledge point, browsing and clicking on the exercise recommendation module, this environment is modeled as an exploratory operating environment for the recommending intelligent body, and each time the intelligent body generates a recommended exercise set, i.e., a question. The structure of the overall reinforcement learning-based thought exercise recommendation model is schematically shown in Figure 7, in which the recommending intelligent body makes strategy decisions based on the learner’s knowledge state and recent answer behavior, and the current action and observed sequence can be observed as: \[\label{GrindEQ__10_}\tag{10} S_{t} =a_{1} \left(Q_{n_{1} } \right),s_{1} ,a_{2} \left(Q_{n_{2} } \right),s_{2} ,\ldots ,a_{t-1} \left(Q_{\left. n_{t-1} \right)} \right),s_{t},\]
where \(Q_{n_{i} }\) is the current generated action i.e. recommendation set, i.e. \(\left\{q_{1} ,q_{2} ,\ldots ,q_{n} \right\}\), which is the action of the recommending intelligence \(a_{t} ,s_{t}\) is the current knowledge state of the learner. Therefore, the current process is modeled as a Markov decision-making process, and it is assumed that the current stage of test recommendation and learning will end and the sequence is discrete, and then the current problem is solved using reinforcement learning methods.
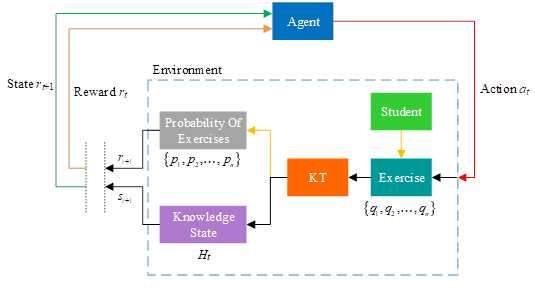
The environment state, i.e., the intelligent body state, is denoted as the current knowledge state of the current learner, denoted as \(s_{t}\), for the current time window, and the knowledge state is obtained from the trained knowledge model, i.e.,: \[\label{GrindEQ__11_}\tag{11} s_{t} =f\left(h_{t} \right) ,\]
where \(h_{t}\) is the learner’s implicit knowledge state of the knowledge model and \(f(\cdot )\) is the discretized processing function. The change of the environment state changes continuously with the learner’s learning process and question-answering process, which is accomplished by constant timed training. The action set is the exercises in the entire teacher-uploaded exercise resource base \({\rm {\rm A}}_{T}\) in the learner’s current learning phase, and each action \(a_{t}\) selected by the intelligent body is the set of exercises to be recommended \(\left\{q_{1} ,q_{2} ,\ldots ,q_{n} \right\}\in Q_{n}\), while \(Q_{n} \in {\rm {\rm A}}_{T}\). Normally, the number of exercises in the recommended set \(N\) is set as a constant 1 or 2.
In this study, five university Civics courses, including Overview of the Basic Principles of Marxism, Introduction to Mao Zedong Thought and Socialism with Chinese Characteristics, Essentials of Modern Chinese History, Foundation of Ideological and Moral Cultivation and Law, and Forms and Policies, were selected as the data sources for the exercises and the data sets of the learners’ answer records. Since the original learners’ answer record data obtained were somewhat different from the experimental data needed for this study, the original answer record data needed to be preprocessed before the experiment.
The two features in this study have different value ranges for the exercise difficulty value and the learner proficiency level value, so the two feature data need to be normalized first, and their value ranges are both mapped in the range of [0,1].
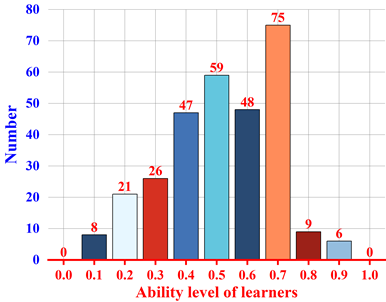
The Civics answer records of some learners were selected as the item information data, and the estimated learner competency level values were obtained after finishing the calculation and were counted into the learner competency level distribution as shown in Figure 8. The horizontal coordinate in the figure is the division interval of the learner competence level parameter \(\theta\), and the vertical coordinate is the number of people in the corresponding competence level interval. From the figure, it can be seen that the learners’ proficiency level is divided into 9 intervals, i.e., intervals 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, and 0.9. The number of people included were 8, 21, 26, 47, 59, 48, 75, 9, and 6, and learners in the same interval were considered to have the same level of competence.
The purpose of the intelligent body in reinforcement learning is to find the optimal path to obtain the maximum reward through learning, the reward is the feedback of the environment on the selection and execution of the action during the learning process, the execution of a poor action to obtain a small reward or even punishment, then the probability of the next time that the action is selected to be executed will become smaller. If an optimal action gets the maximum reward, the probability that the next optimal action will be selected for execution will become larger. A reasonable reward strategy can improve the efficiency of model training, so it is very important for the design of the instant reward strategy.
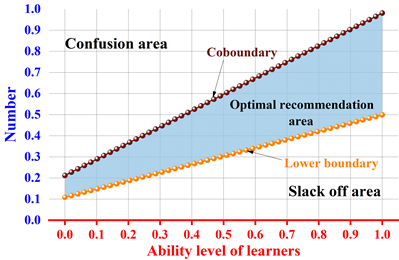
The purpose of this Civics course assisted teaching system is to recommend to the learners, can improve the five university Civics course exercises, to the learner’s ability level and the difficulty of the topic to build the learner’s optimal recommendation model as shown in Figure 9. The upper and lower lines in the figure represent the upper and lower boundaries of the “Civics and Political Science Exercise Recommendation”, and the upper boundary is the “confusion area” of the learners, which indicates that the learners’ ability level is insufficient, but the difficulty of the exercise questions is too high, resulting in the incorrect rate of answering the questions, and it is easy to be puzzled by the learning content. This area indicates that the learner’s ability level is insufficient but the difficulty of the practice questions is too high, resulting in a low rate of correct answers and easy confusion about the content. Below the lower boundary is the “slack zone”, which indicates that the learner’s ability level is high, but the difficulty of the practice questions is too low, resulting in too high a correct answer rate, and the learner is easily bored with the study. The area between the two boundaries is the “optimal recommendation zone”. For example, when the learner’s ability level is 0.9, the optimal recommended difficulty interval for Civics exercises is [0.5 1.0]. Therefore, the optimal path for the reinforcement learning objective is to find two boundaries, and the corresponding difficulty of the topics between the boundaries is recommended to the learners with the corresponding ability level, which can complete the Civics and Politics exercise recommendation task.
As can be seen from the network diagram of Civics exercises constructed in the previous section, the knowledge point relevance is the weight of the paths in the directed relationship graph, and the direction of the paths is the knowledge points that are easier to learn. Learning directedness aims to calculate the degree of association between knowledge points, and use the forward and backward relationship to generate recommended actions, and the directed generation of learning paths can significantly improve the efficiency of Civics learning and enhance the overall Civics learning effect. Its effectiveness in the recommendation process can be verified by the distribution of the relevance of each knowledge point in the original dataset and the distribution of the relevance of knowledge points in the recommendation process.
A comparison of the distribution of the relevance of knowledge points in the Civics course is shown in Figure 10, which shows the distribution of the relevance of knowledge points in the source data (Original) and the recommended sequence of Civics exercises based on reinforcement learning (Q-Learning). The former is the static matrix in the domain knowledge relationship graph, and the latter is the correlation between neighboring knowledge points in all recommended sequences during the recommendation process. The horizontal coordinate is the value taken by the correlation degree, and the vertical coordinate is the ratio. In the source data, the correlation is most distributed around 0.00 and 0.033, with proportions of 0.382 and 0.132, respectively.During the recommendation process, Q-Learning is most distributed at 0.033 and 0.035, with proportions of 0.186 and 0.238, and the two distributions diverge the most at 0.00 and 0.035, which is generated by the algorithm’s optimal decision-making.
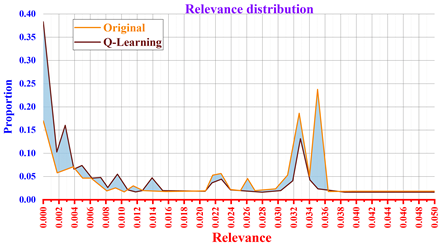
The larger the correlation degree is, the higher the reward value is, and the more the Civics exercise recommendation direction tends to the learning goal. So the correlation degree of 0.035 is less than 0.03 in the source data, but the proportion in the Q-Learning recommendation sequence reaches 0.238.Therefore, it can be shown that the Civics course assisted teaching system based on reinforcement learning is effective for the directedness of Civics learning in colleges and universities.
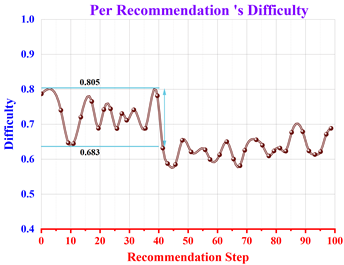
In order to verify the effect of Civics learning progressivity, the trained model is tested with 100 consecutive exercise recommendations, and the changes in the comprehensive difficulty of all recommended Civics knowledge points are recorded.The changes in the comprehensive difficulty in the recommended sequence of Q-Learning are shown in Figure 11, where the horizontal coordinate is the recommended step, and the vertical coordinate is the comprehensive difficulty of the Civics knowledge points recommended in each step. As can be seen from the figure, the comprehensive difficulty has jumped in the recommendation process, but the change is small in the local range. For example, during STEP 0\(\mathrm{\sim}\)40, the comprehensive difficulty stays between 0.683-0.805, and during STEP 40\(\mathrm{\sim}\)60, the learning progressivity is effective for the overall learning effect. The comprehensive difficulty remained around 0.65, and there were successive recommendations of exercises on the same knowledge points. In summary, the analysis shows that the Civics Course Assisted Teaching System based on reinforcement learning is effective for students’ learning progressivity of Civics knowledge points.
If we want to verify the effectiveness of the auxiliary teaching system of the Civics course in colleges and universities for learning engagement, we can compare the change of the average reward value when the learning factor is different values under the same learning state. Comparison of learning factor \(\alpha\) for 0.2, 0.5, the average reward value of 500 Episode training process changes. The results of the changes in the average reward values for different values of learning factor \(\alpha\) are shown in Figure 12. It can be seen that when the learning factor \(\alpha\)=0.2, the average reward value is between 0.536 and 0.738 with a small upward trend. When \(\alpha\)=0.5, the average reward value is between 0.723 and 1.262 and there is a clear upward trend in the early period.
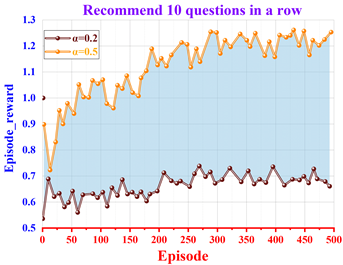
From the analysis, it can be seen that \(\alpha\)=0.2 is inconsistent with the current learning state, resulting in a large deviation of the recommended direction of Civics exercises from the learning objectives, so its average reward value is much worse than that at \(\alpha\)=0.5. This can show that the Civics course assisted teaching system based on reinforcement learning is effective for the engagement of Civics learning.
Aiming at the current problem that the learning effect of Civics and Politics in colleges and universities is not obvious, this paper is based on the reinforcement learning algorithm, improves the wise-adaptive learning model, and designs and constructs a highly efficient and stable auxiliary teaching system for Civics and Politics courses for college students. The main research results are as follows:
The detailed design, construction and testing of the auxiliary teaching system for college students’ Civics and Politics courses are completed, and the system realizes the functions of knowledge state assessment and personalized exercise recommendation. When the learning factor is 0.5, the average reward value is between 0.723 and 1.262, and the coverage rate of the recommended exercises is more than 0.65, and the mastery rate is more than 0.88, which is practical to a certain extent.
The auxiliary teaching system for college students’ Civics courses designed in this paper has a certain degree of exploration and innovativeness, which provides a useful reference for the progress of the whole Civics education, and has an important practical significance for saving students’ learning time, enhancing students’ learning ability and improving the teaching quality of Civics education.




